
Hostwinds虚拟主机搭建网站怎么样?
Hostwinds是一家提供了全面美国主机服务的公司,其虚拟主机在性能和功能上都有着一定的亮点,很多用户选择Hostwinds虚拟主机来搭建网站,本文也从几个方面其进行了介绍,那么就一起来了解下Hostwinds虚拟主机搭建网站怎么样吧。 ...

Hostwinds是一家提供了全面美国主机服务的公司,其虚拟主机在性能和功能上都有着一定的亮点,很多用户选择Hostwinds虚拟主机来搭建网站,本文也从几个方面其进行了介绍,那么就一起来了解下Hostwinds虚拟主机搭建网站怎么样吧。 ...

 官方网站:https://www.747it.com
官方网站:https://www.747it.com
 9.9元云服务器购买链接:https://www.747it.com/cart?action=configureproduct&pid=26
9.9元云服务器购买链接:https://www.747it.com/cart?action=configureproduct&pid=26
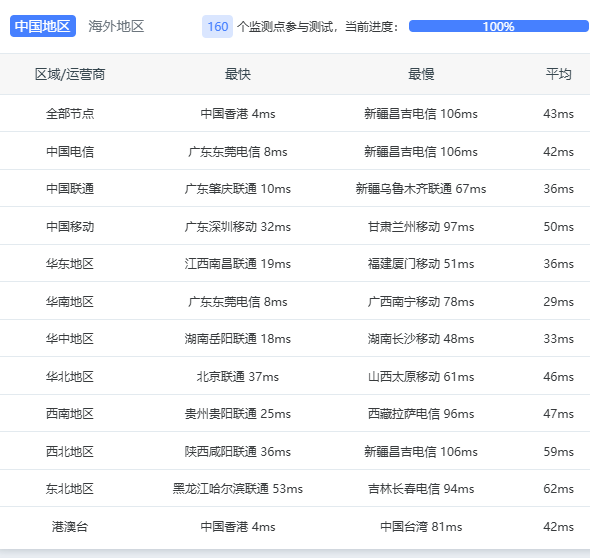 回国线路平均40ms左右,三网直连高峰期不跳线路!
回国线路平均40ms左右,三网直连高峰期不跳线路!
RustDesk一个高效且安全的远程协助软件,支持多平台且免费开源的。本文将以为例,为大家详细介绍在莱卡云云服务器上部署RustDesk服务器的教程,希望可以对大家有所帮助。
莱卡云官网:
文章目录1、一台云服务器
用户需要安装Linux,脚本经过测试,可与CentOS Linux 7/8、Ubuntu 18/20和Debian配合使用。具有1个CPU、1GB内存和10GB磁盘的服务器足以运行RustDesk。
2、用于SSH连接服务器工具,进行安装等操作。
3、下载并安装RustDesk客户端。
二、创建并配置莱卡云云服务器1、进入莱卡云官网,点击“免费注册”并登录。
2、点击“产品服务”,可以看到很多产品,本文选择(CN2)。
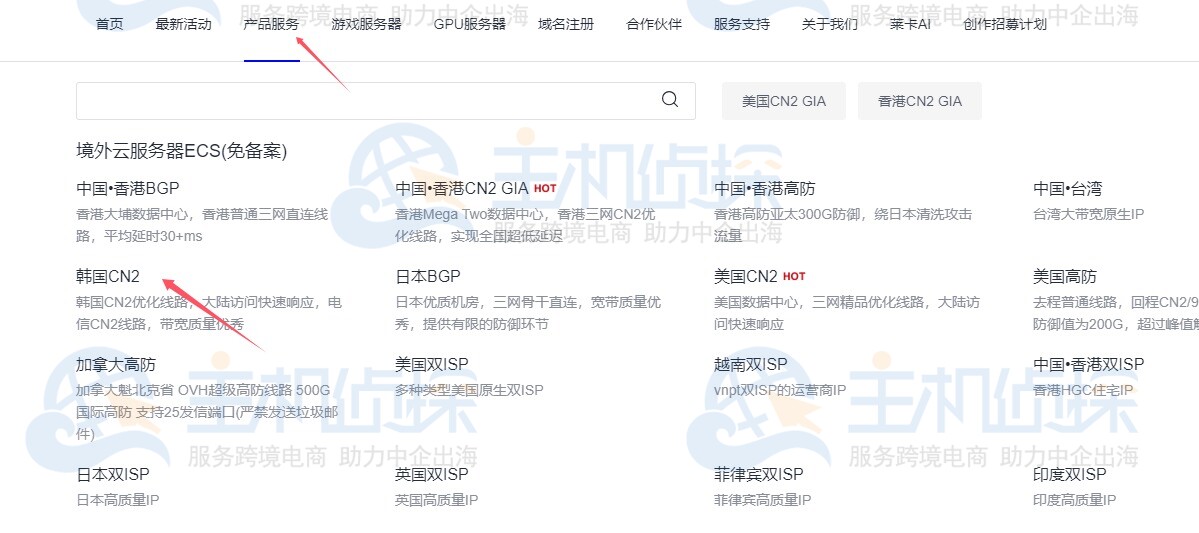
3、在以下界面可以看到三种方案,用户可以按需选择,本文选择的是韩国CN2大带宽云服务器,点击“前往选购”。

莱卡云韩国CN2云服务器方案推荐
| 方案 | CPU核 | 内存 | 硬盘 | 带宽 | IP地址 | 线路 | 价格/月 | 购买链接 |
| 韩国CN2 | 1–32C | 1–128G | 20–100G | 3–20Mbps | 1IPv4(原生) | CN2 | ¥38起 | |
| 韩国CN2大带宽 | 1–32C | 1–128G | 20–100G | 20–50Mbps | 1IPv4(原生) | CN2 | ¥40起 | |
| 韩国ISP | 1–32C | 1–128G | 30–200G | 100–300Mbps | 1IPv4(双ISP) | 国际线路 | ¥68起 |
《》
4、系统选择Ubuntu的20版本,地区选择韩国地区,配置选择1个CPU,1GB内存,20GB硬盘,带宽20Mbps。
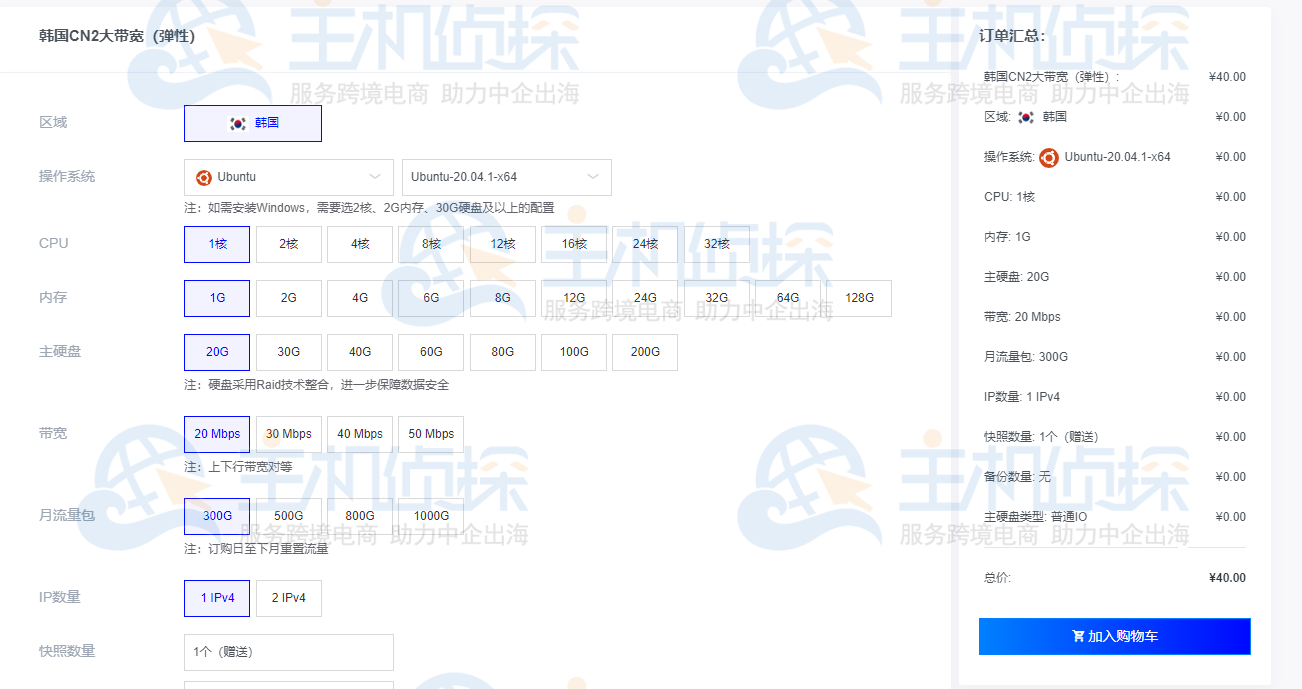
5、确认无误后,付款即可,等待服务器创建成功。
6、用户需要在服务器的防火墙中开放RustDesk需要的端口,放行以下端口:
TCP:21115-21119
UDP:21116
注:有些服务器Linux系统预装了防火墙,用户需要给以上端口放行,或者关闭防火墙。
三、安装RustDesk服务器1、SSH连接到用户的服务器。
2、更新系统源和软件
apt update //更新源
apt upgrade //更新软件
3、系统重启好后,粘贴RustDesk Server一键安装脚本,回车开始安装。
一键安装脚本:
wget https://raw.githubusercontent.com/techahold/rustdeskinstall/master/install.sh
chmod +x install.sh
./install.sh
一键更新脚本:
wget https://raw.githubusercontent.com/smianao/rustdeskinstall/master/update.sh && chmod +x update.sh && ./update.sh
查看并复制密钥Key备用。
4、主控端电脑安装RustDesk客户端。
主界面依次点击设置-网络-解锁网络设置,ID/中继服务器设置如下:
ID服务器:为你云服务器IP地址
中继服务器:为你云服务器IP地址
API服务器:空
Key:上一步获取的key
ID/中继服务器界面,可导入导出配置。
将Windows客户端名称修改为如下格式,发给被控电脑使用即可。
rustdesk-host=<你的服务器IP/域名>,key=<你的key>.exe
本教程将介绍如何使用 Amazon CloudFront 分发网站应用内容,降低终端用户的访问延迟。
Amazon CloudFront 依托其全球数据中心网络,通过将内容缓存到靠近终端用户的位置来缩短分发时间,从而实现内容加速。当边缘站点中没有所需内容时,CloudFront 会从源站(例如 Amazon Simple Storage Service,即 Amazon S3 存储桶、Amazon Elastic Compute Cloud,即 实例、ELB 负载均衡器,或你自己的 Web 服务器)获取内容。CloudFront 可用于分发你的整个网站或应用,涵盖动态内容、静态内容、流媒体内容以及交互式内容等多种类型。
在后续步骤中,你将把 Amazon S3 存储桶配置为源站,并通过网页浏览器测试你的分发情况,确保内容能够正常分发。
本教程中的所有操作均符合 AWS 免费套餐使用条件,不会产生额外费用。
AWS官网:
具体注册教程:《》
《》
文章目录本步骤中将把示例静态内容上传到 Amazon S3 存储桶。在后续步骤中,该存储桶将用作 CloudFront 的源站。对于包含图片、视频、HTML 页面、.css 文件和 .js 文件等静态内容的 Amazon CloudFront 源站而言,Amazon S3 是一个非常合适的选择。首先,请创建一个 HTML 文件。
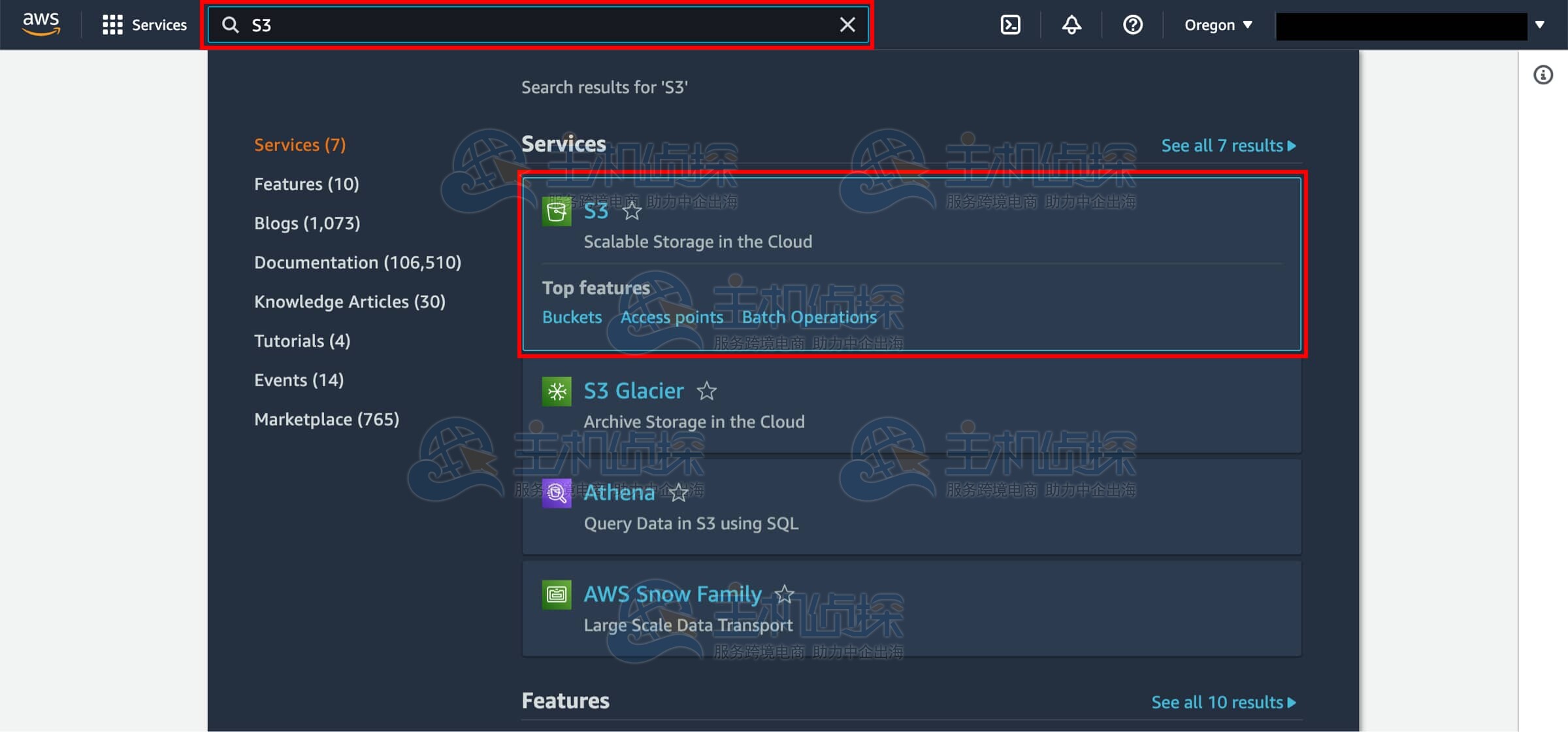
1、进入 Amazon S3 控制台
点击此链接后,AWS 管理控制台将在新的浏览器窗口中打开。在搜索栏中输入“S3”,然后选择“S3”进入控制台。
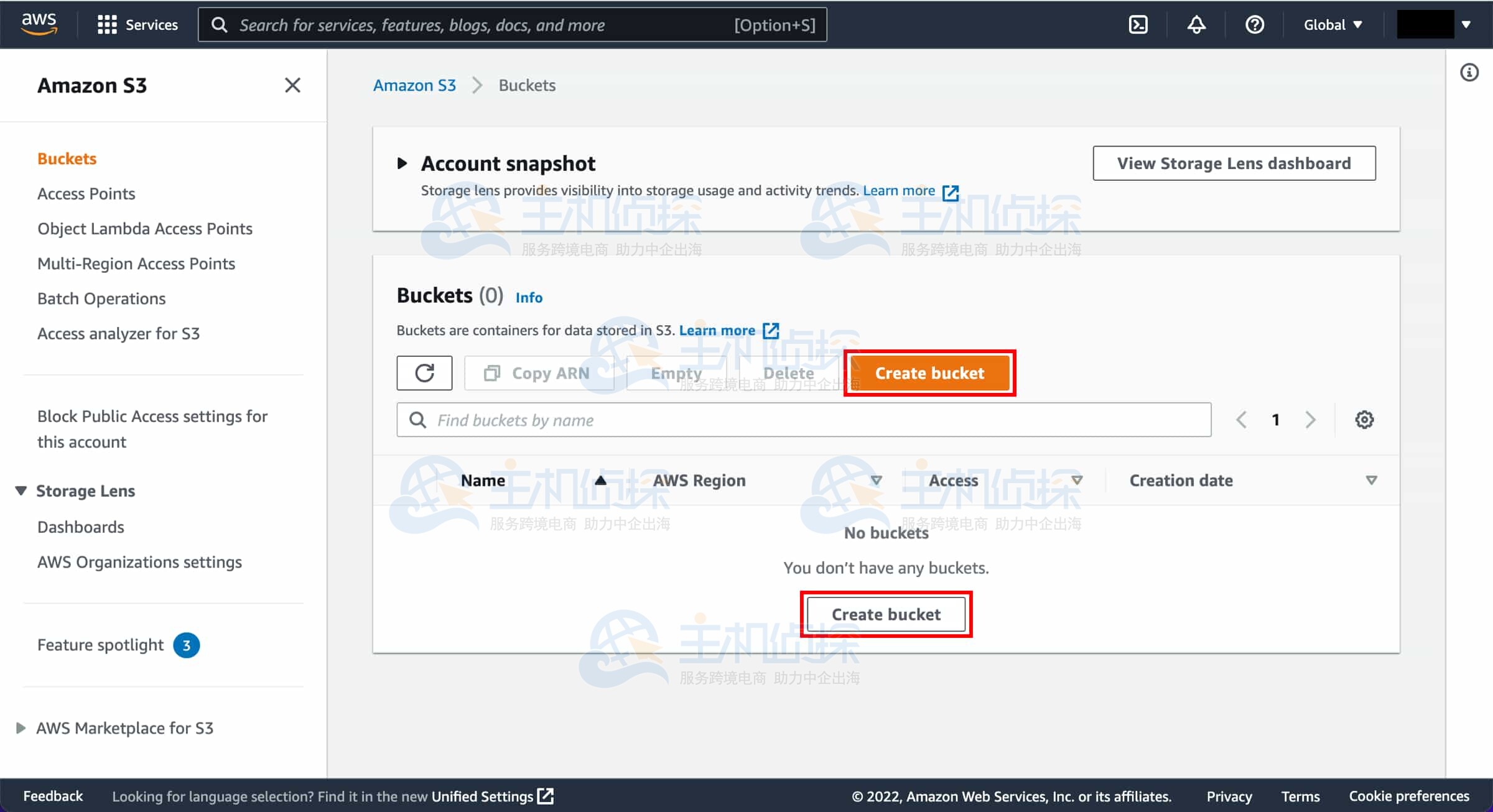
2、创建 S3 存储桶
在 S3 控制台主页,点击“创建存储桶”(Create bucket)。
若你是首次创建存储桶,将看到类似此处所示的界面;若你已创建过 S3 存储桶,S3 控制台将列出所有已创建的存储桶。
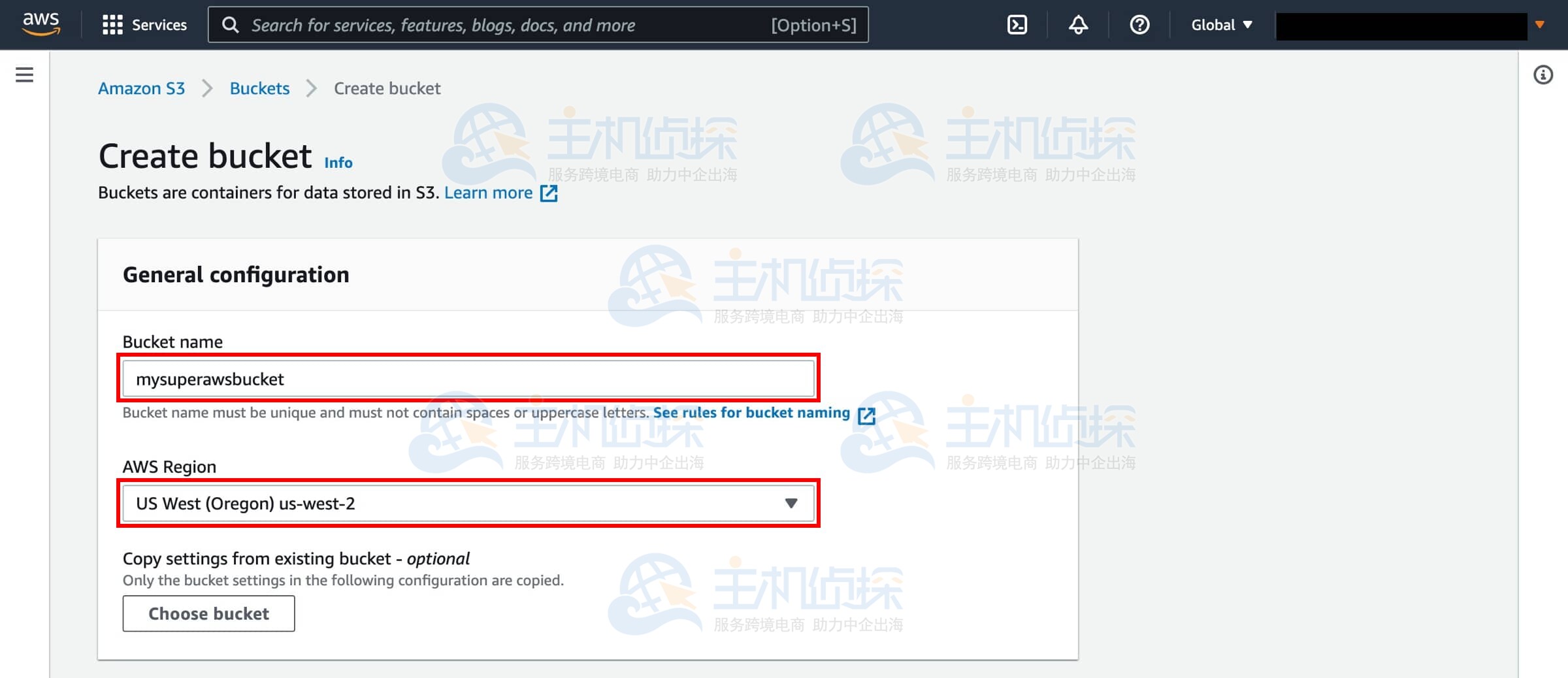
3、输入存储桶名称
输入一个唯一的存储桶名称。S3 存储桶名称在所有现有 Amazon S3 存储桶名称中必须是唯一的,此外还有其他一些关于 S3 存储桶名称的限制规则。然后选择创建存储桶的区域。
4、设置权限配置
你可以为 存储桶设置权限配置。默认情况下,S3 对象设置为私有状态。由于需要使图片能够被公开读取,你需在“对象所有权”(Object Ownership)下选择“启用 ACL”(ACLs enabled),取消勾选“阻止所有公共访问”(Block all public access),并勾选“我确认当前设置可能导致此存储桶及其包含的对象变为公开状态”(I acknowledge that the current settings might result in this bucket and the objects within becoming public.)。
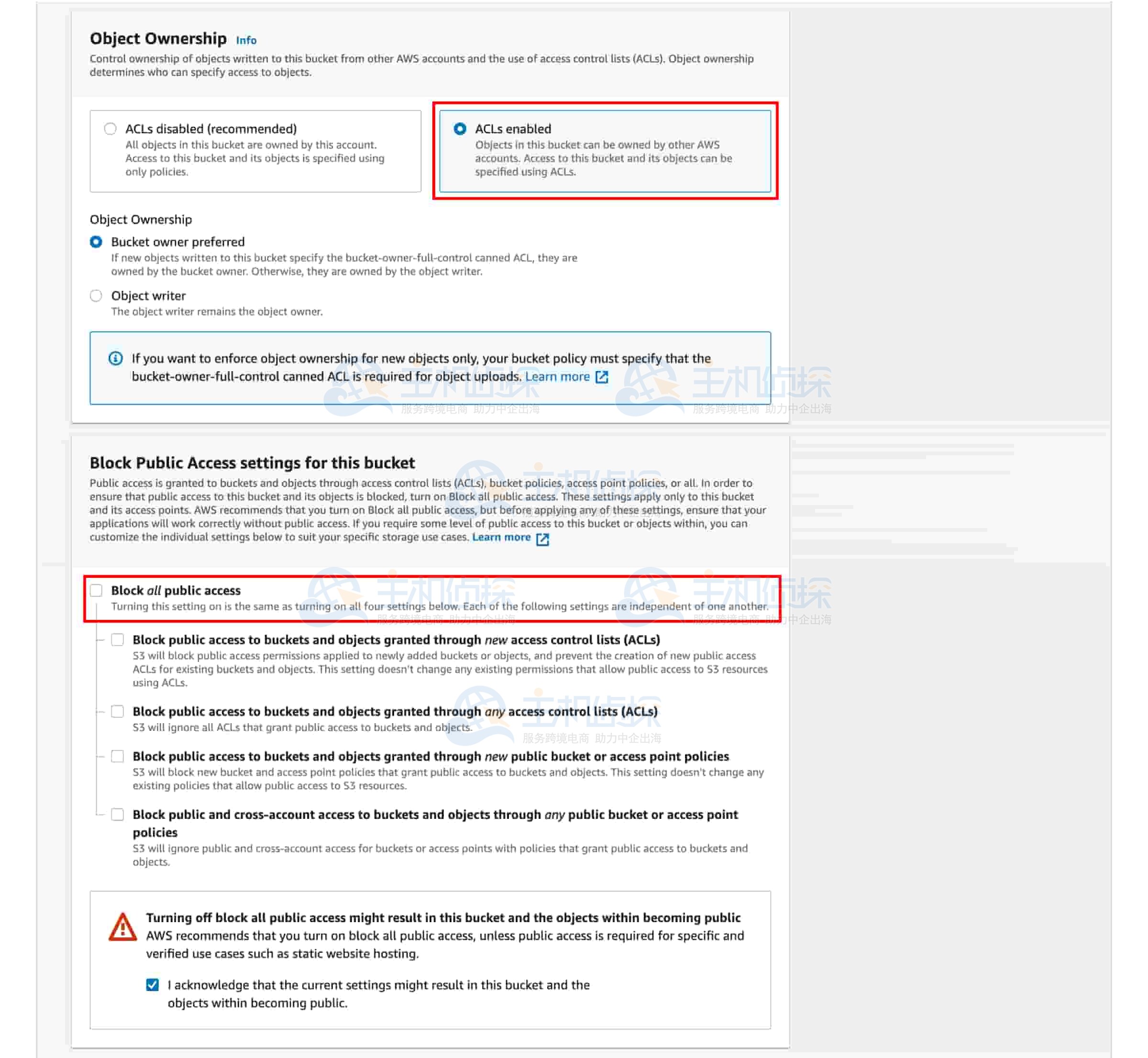
5、创建存储桶
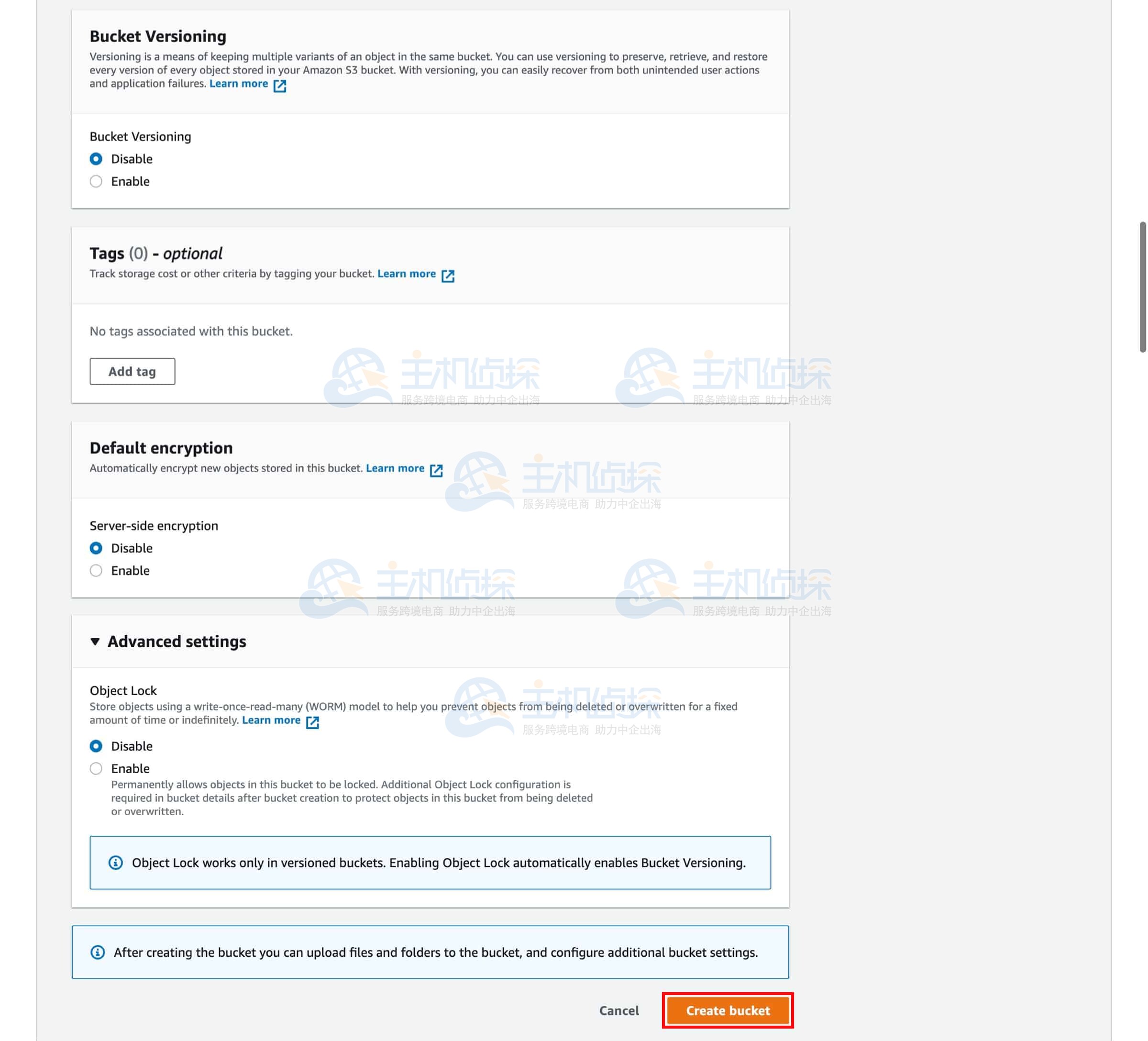
S3 存储桶提供了许多实用选项,包括版本控制(Versioning)、服务器访问日志(Server Access Logging)、标签(Tags)、对象级日志(Object-level Logging)和默认加密(Default Encryption)等。本教程中我们暂不启用这些功能。
点击“创建存储桶”(Create bucket)。
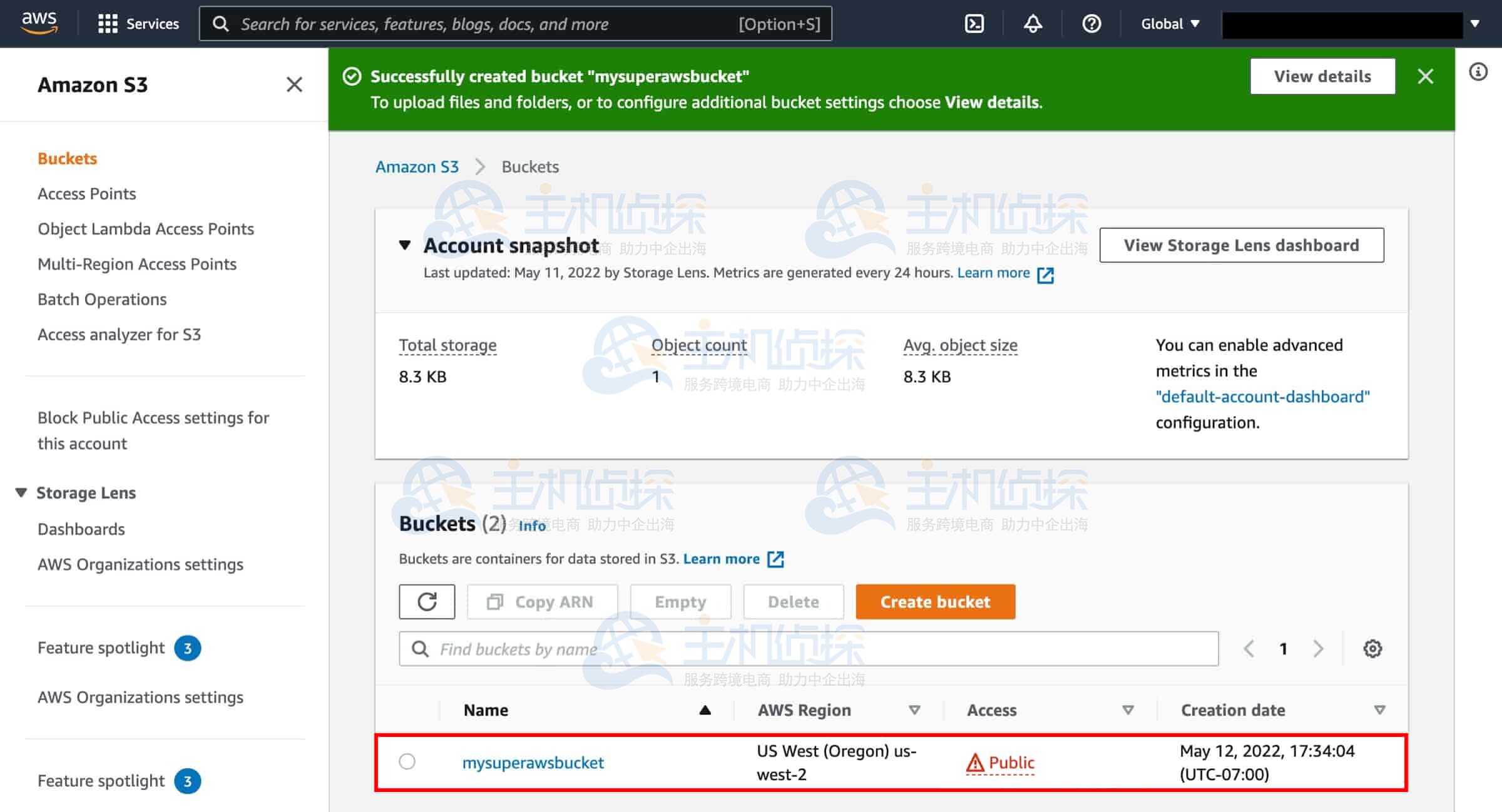
6、进入新创建的存储桶
你将在 S3 控制台中看到新创建的存储桶,点击该存储桶的名称进入存储桶页面。请注意,你的存储桶名称与右侧截图中显示的名称可能不同。
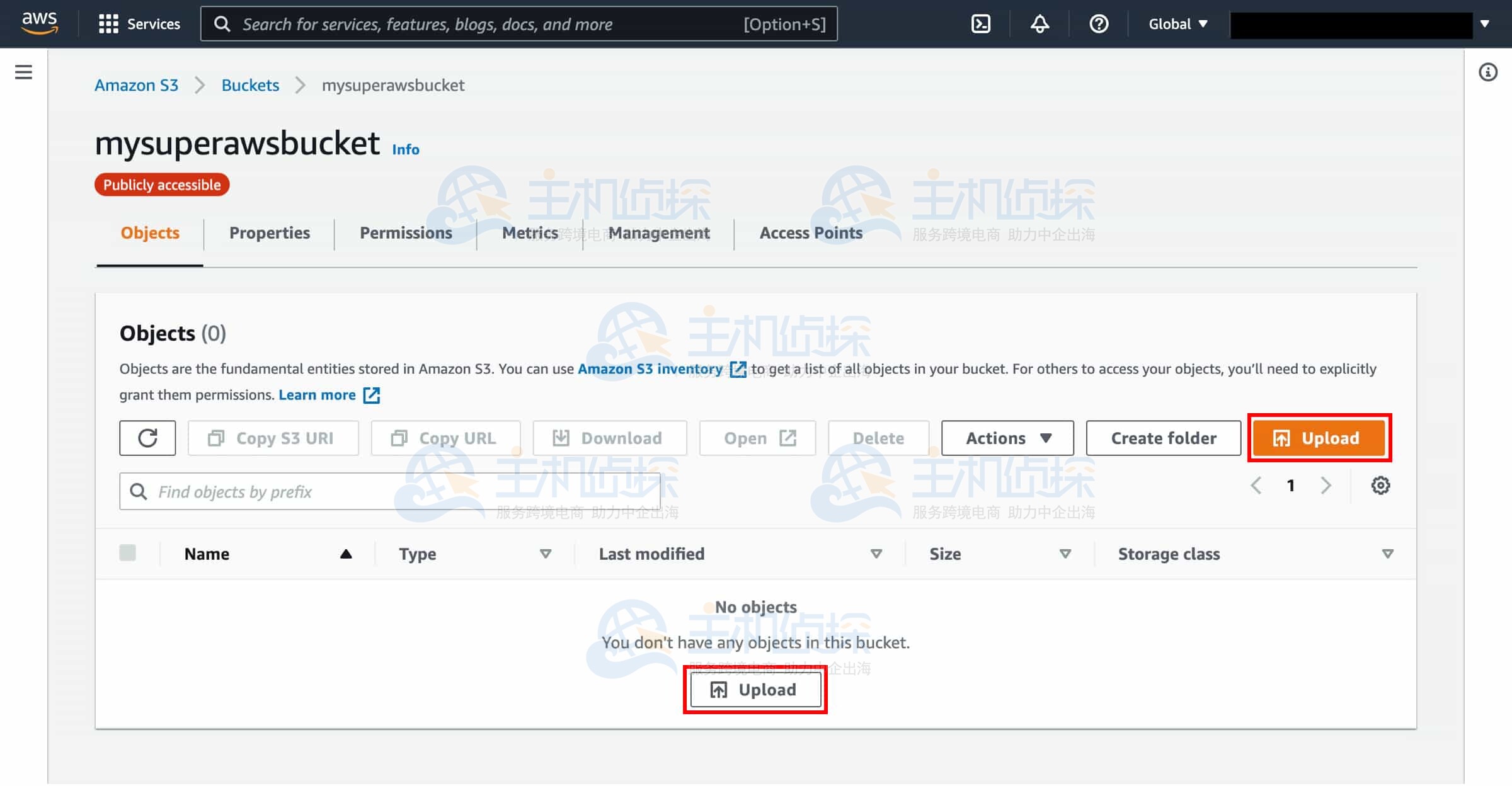
7、选择上传
此时你处于存储桶的主页,点击“上传”(Upload)。
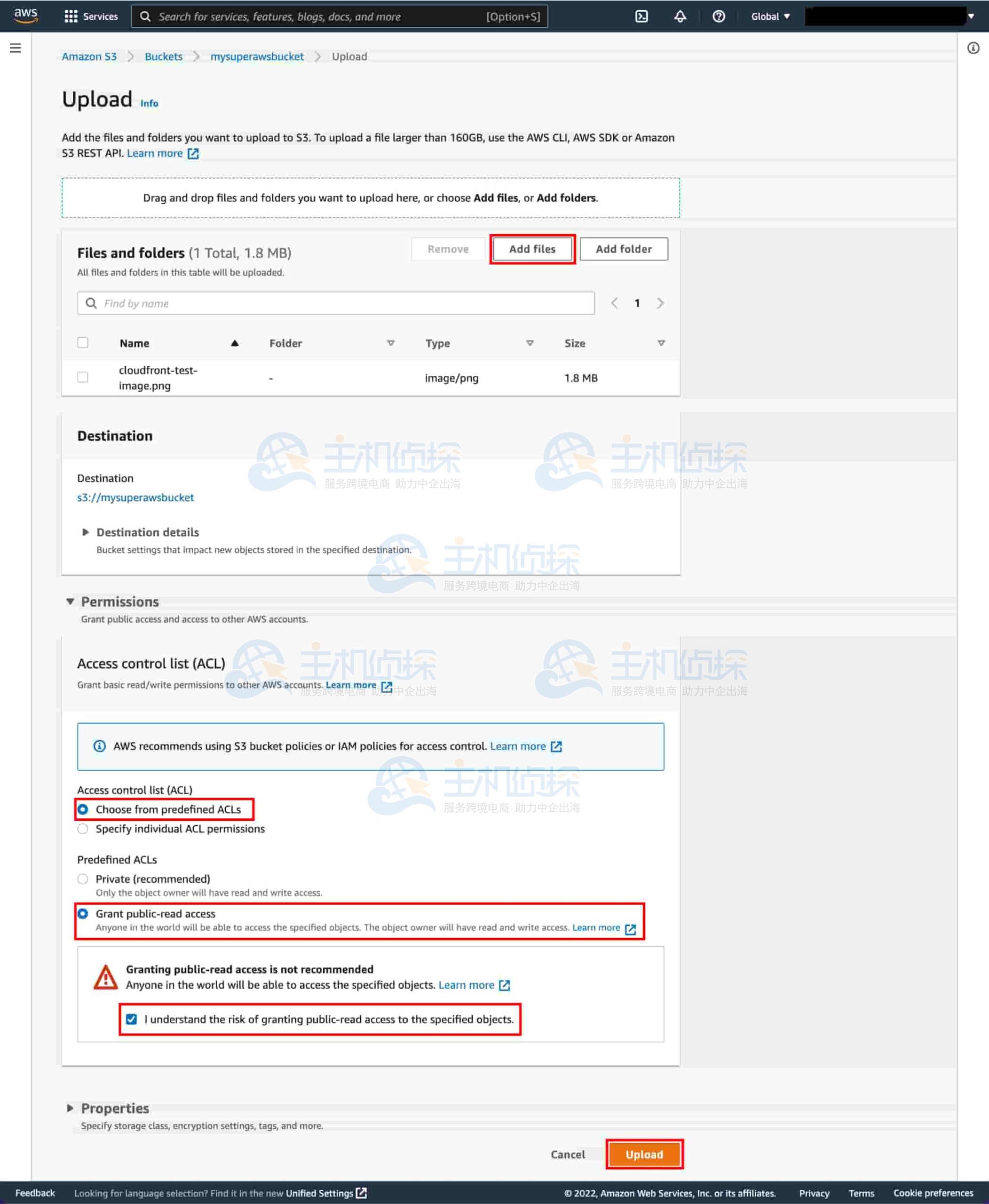
8、上传示例内容
通过点击“添加文件”(Add files)并选择文件,或直接将 cloudfront-test-image.png 文件拖到上传框中,来上传该文件。
展开“权限”(Permissions)下拉菜单,选择“从预定义 ACL 中选择”(Choose from predefined ACLs),然后选择“授予公共读取权限”(Grant public-read access),并勾选“我了解向指定对象授予公共读取权限的风险”(I understand the risk of granting public-read access to the specified objects.)。
点击“上传”(Upload)。
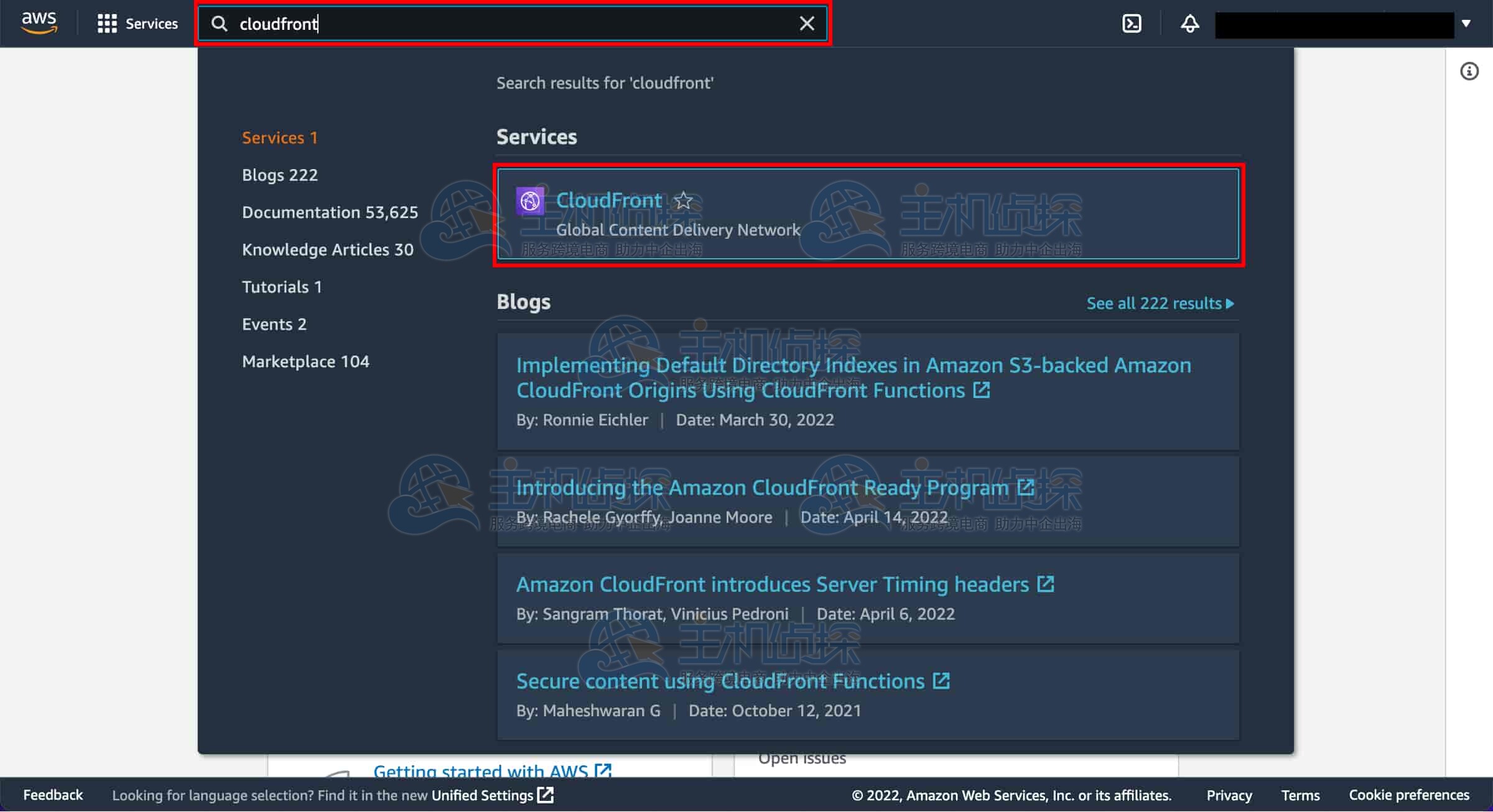
打开 CloudFront 控制台:点击此链接后, 管理控制台将在新的浏览器标签页中打开。在搜索栏中输入“CloudFront”,然后选择“CloudFront”进入控制台。
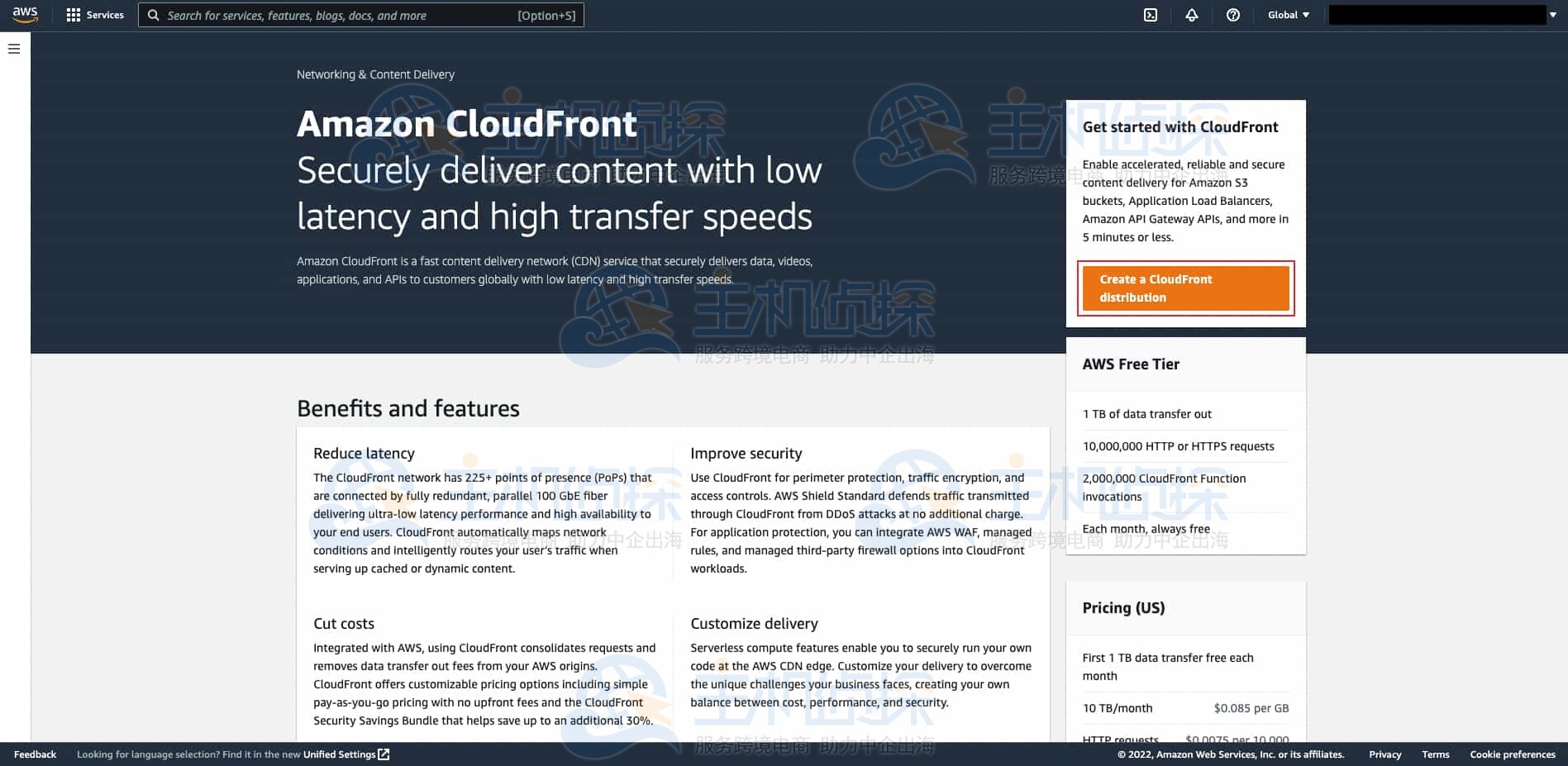
点击“创建 CloudFront 分发”(Create a CloudFront distribution)。
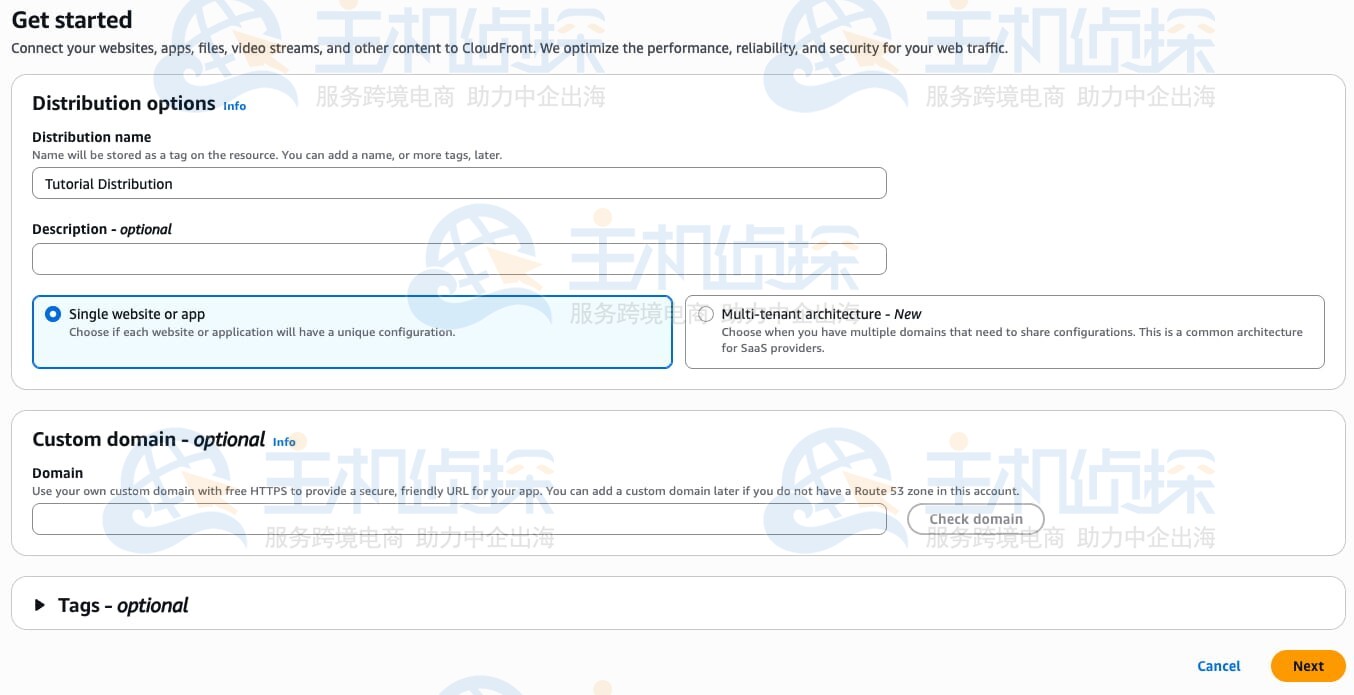
1、开始配置
将你的网站、应用、文件、视频流和其他内容关联到 CloudFront,我们会为你的网络流量优化性能、可靠性和安全性。
在“分发选项”(Distribution Options)下,输入标准分发的“分发名称”(Distribution name),也可根据需要填写描述信息。
确保选择“单一网站或应用”(Single website or app)。
本教程中,我们暂不进行“自定义域名”(Custom domain)和“标签”(Tags)的设置,保留这两个可选字段为空即可。
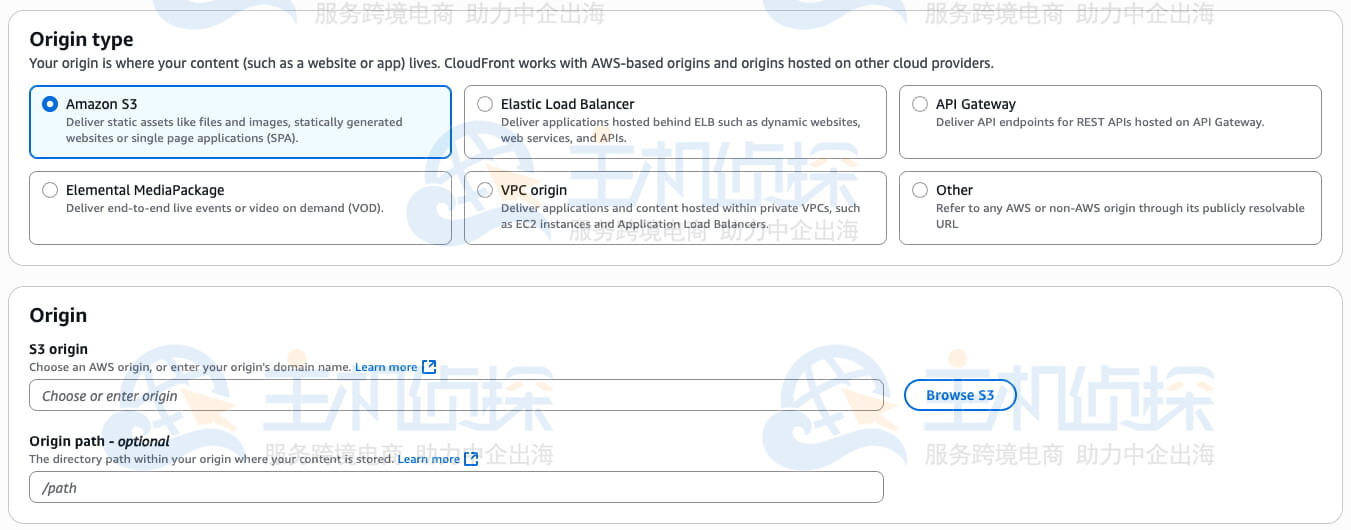
2、指定源站
在“源站类型”(Origin type)下,选择“Amazon S3”(默认已选中该选项)。在“源站”(Origin)部分,点击“浏览 S3”(Browse S3)按钮,选择你存储 cloudfront-test-image.png 文件的 S3 存储桶名称。
此页面上的其他设置可保持默认不变,这样会自动为你的分发配置好从 S3 缓存内容的正确设置。
3、启用安全性
本教程中,我们选择“不启用安全保护”(Do not enable security protections)。但对于在 CloudFront 上长期运行的非教程类工作负载,强烈建议启用安全保护功能。

查看你的更改,确保所有设置均正确无误后,点击“创建分发”(Create Distribution)。
创建好你的分发后,该分发对应的“状态”(Status)列的值将从“部署中”(Deploying)变为分发部署完成的日期和时间。
注意:此过程可能需要几分钟时间才能完成,请耐心等待。
五、创建分发1、创建 HTML 文件
打开你电脑上的文本编辑器,复制并粘贴以下 HTML 代码:
<html>
<head>My CloudFront Test</head>
<body>
<p>My text content goes here.</p>
<p><img src=”http://域名/对象名称” alt=”my test image”>
</body>
</html>
将“域名”(domain name)替换为 CloudFront 分配给你的分发的域名(例如 d111111abcdef8.cloudfront.net),将“对象名称”(object name)替换为你在 Amazon S3 存储桶中的图片文件名(本示例中为 cloudfront-test-image.png)。
将该文本保存为 mycloudfronttest.html 文件。
在网页浏览器中打开此 HTML 文件,验证链接是否有效。

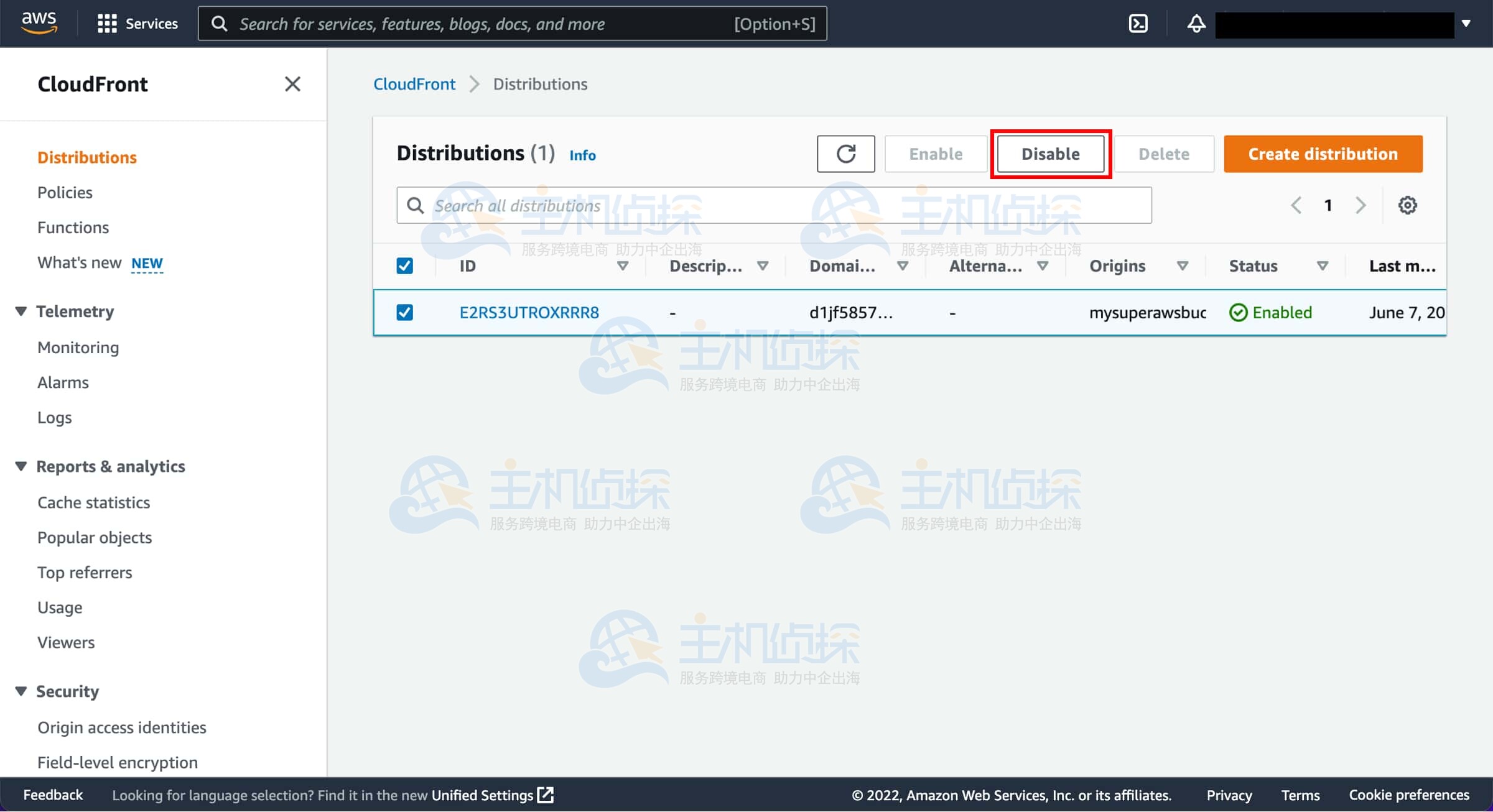
1、选择要禁用的分发
勾选你创建的分发对应的复选框,然后选择“禁用”(Disable)。
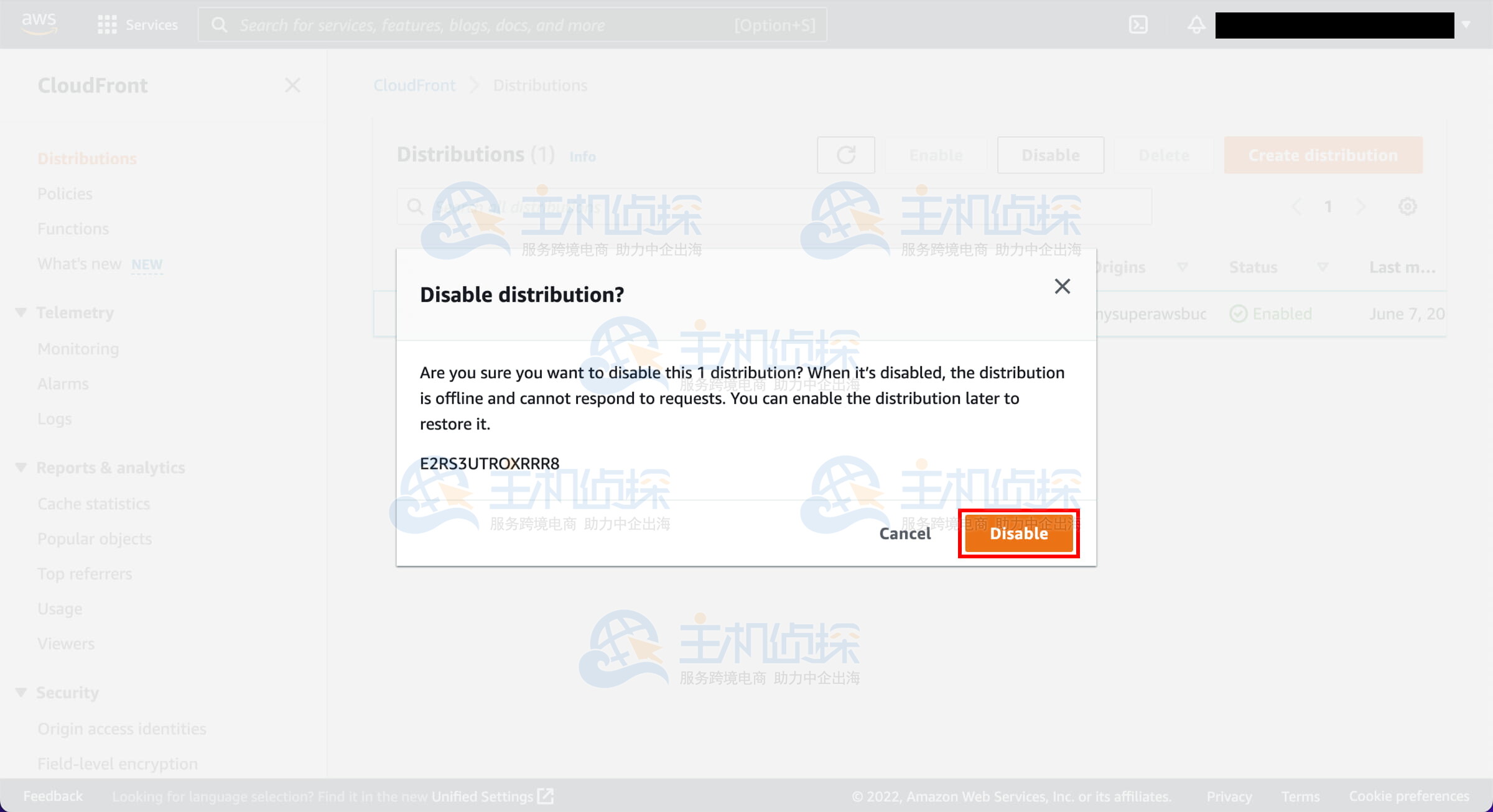
2、确认禁用分发
系统将提示你确认,点击“禁用”(Disable)。
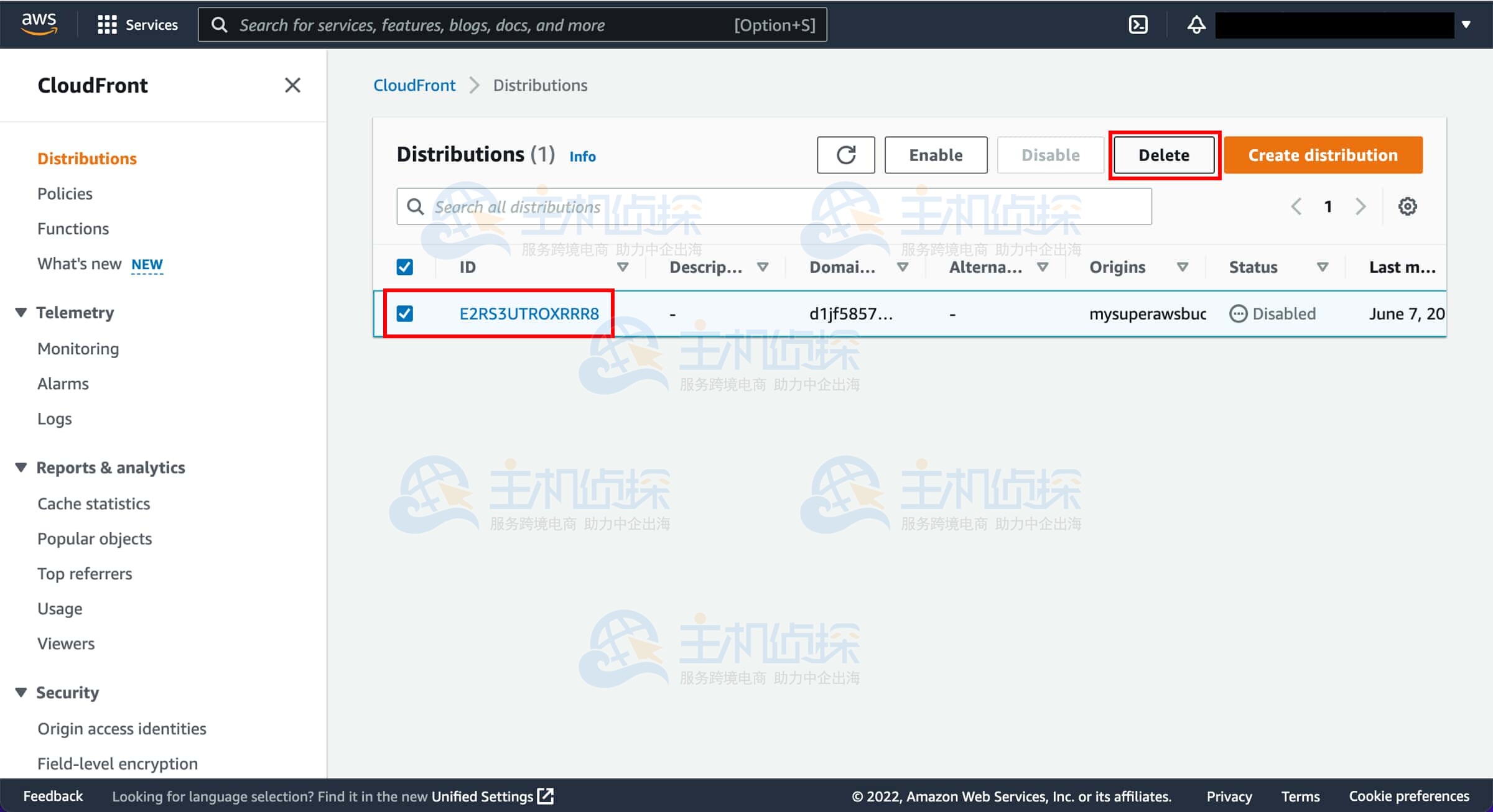
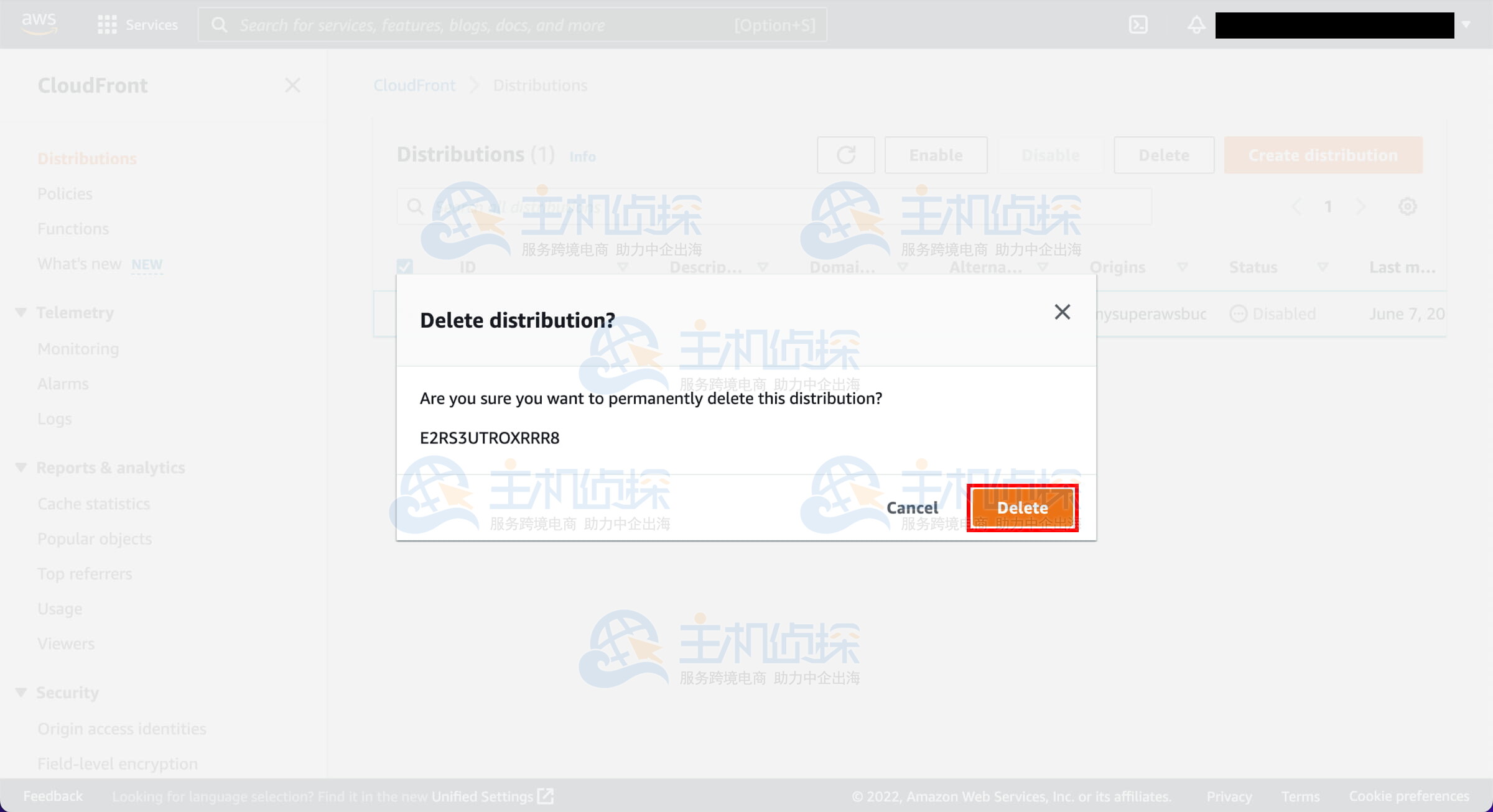
7、选择要删除的分发
勾选你创建的分发对应的复选框,然后选择“删除”(Delete)。
4、确认删除分发
系统将提示你确认,点击“删除”(Delete)。
云服务器远程连接失败怎么操作?在国内或者是远程连接失败后,首先需要弄清导致云服务器远程连接的原因,是网络环境的限制,还是服务器配置问题,亦或者是操作系统和客户端的因素,之后根据特定步骤排查云服务器远程连接失败的原因,并根据原因进行相应的策略调整。
文章目录1、网络环境
无论是使用SSH、RDP还是其他远程访问协议,客户端都必须通过公网或专用网络访问云服务器的IP地址。如果本地网络出现丢包、高延迟或受到防火墙限制,客户端可能无法与服务器建立稳定的连接。
例如在高峰时段,家庭或办公室网络的带宽拥塞可能会增加丢包,导致连接请求无法及时到达服务器并触发超时。
解决方案包括测试网络延迟和丢包,使用 Ping 和 Traceroute 等工具确认平滑路径,并在必要时切换网络或使用更稳定的专线。
2、服务器端配置
如果云服务器的防火墙或安全组规则没有正确打开相应的端口,客户端请求将无法通过,并且连接将被阻止。
例如SSH 默认使用端口 22。如果防火墙策略仅允许访问某些 IP 地址,并且客户端 IP 地址不在允许列表中,则不会建立连接。同样RDP默认使用端口 3389,如果安全组策略阻止此端口,则远程桌面连接也将超时。
因此必须检查云服务器的防火墙配置、国内/国外云服务提供商的安全组规则以及端口访问状态,通常可以使用 Telnet 或 Nc 连接到服务器端口以确认访问。
3、操作系统
例如Linux系统可能无法响应请求,因为 SSH 服务未启动、出现故障或被进程占用。由于远程桌面服务被禁用、故障或系统资源不足,Windows系统可能无法及时处理连接请求。
此外如果服务器的 CPU 或内存使用过高,操作系统可能无法及时响应新的远程请求,从而导致连接超时。对于这些问题,需要首先登录服务器控制台或使用、小皮面板等云服务器管理面板来验证远程访问服务是否正常运行并检查系统负载。
4、客户端工具设置
不同的远程访问工具对于超时、重试尝试和加密方式有不同的默认设置。如果默认超时时间过短,即使是最轻微的网络波动也可能触发连接超时。解决方案包括适当增加超时、增加重试次数、选择更稳定的加密算法以及升级客户端软件以确保与服务器的兼容性。
5、云服务器带宽和网络连接
特别是对于跨境接入,连接质量直接影响连接稳定性。如果服务器为海外云服务器,跨境链路的高延迟和丢包可能会导致客户端连接请求无法在指定时间内完成三次握手,从而导致超时。
为了解决这个问题,可以选择高质量的国际连接或使用CDN等方式进行优化,以确保跨境访问的低速和稳定性。此外如果服务器的带宽有限或高度拥塞,也会无法及时建立新连接,因此需要监控服务器带宽使用情况。
点击链接:
本站整理了2025年网络连接稳定且访问速度低的国内外云服务器商家,感兴趣的用户可以点击《》了解详情。
6、安全设置
除了上述常见问题外,安全策略还可能导致远程连接超时。例如一些云服务提供商提供高级安全功能,在检测到异常访问或高频连接请求时主动阻止或延迟响应,从而导致连接超时。
在这种情况下,请登录控制台并查看安全日志,以确定策略是否阻止了连接,并相应地调整策略。此外如果通过跳转服务器进行访问,跳转服务器上的资源限制也可能间接导致远程连接超时。
二、排查远程云服务器连接失败步骤在实践中,排除连接超时需要特定的顺序。首先确认本地网络是否正常运行,尝试不同的网络或使用命令行工具来测试延迟和丢包情况。接下来检查服务器的防火墙、安全组、端口开放性以及远程服务是否正常运行和运行。之后监控服务器的资源使用情况和带宽使用情况,必要时优化性能或增加带宽,接着验证客户端工具设置,包括超时、协议版本和加密算法等。最后验证安全策略和中间网络设备,确保它们不会妨碍正常的连接作。
在排除远程连接超时,日志记录的重要性也至关重要。通过查看服务器和客户端日志,可以确定连接请求是否到达了服务器,是否被防火墙阻止,或者是否在内部被拒绝。
日志分析可以显著减少故障排除时间,并有助于查明问题原因。对于大型企业或高并发业务,可以考虑部署监控系统,实时监控远程服务状态、网络延迟和带宽使用情况,以便及时发现和解决异常情况。
此外为了提高远程访问的可靠性,可以采取预防措施。例如在云服务器上启用KeepAlive或TCP心跳机制,确保在网络抖动期间不会立即断开连接,合理配置SSH或RDP会话超时参数,防止短暂延迟导致客户端超时。
并使用高质量的网络连接来优化跨境访问,特别是在国际访问需求较高的场景下,配置多个跳转服务器可以实现冗余和负载均衡,进一步降低连接超时的风险。
在跨境接入场景中,选择合适的服务器位置和连接至关重要。例如从中国大陆访问中国香港、韩国或日本的云服务器时,像、HostEase这样提供高质量链路的云服务器(如CN2 GIA和BGP优化链路)可以显著减少延迟和丢包,提高远程连接稳定性。
但是即使使用正确的服务器配置和防火墙规则,使用标准国际链路或带宽拥塞的链路也很容易导致连接超时,因此链路选择和带宽规划应该是远程访问设计的关键组成部分。
简而言之,远程云服务器上的连接超时不是由单一因素引起的,相反它们是由多种因素共同产生的,包括网络环境、服务器配置、作系统状态、带宽和链接质量、客户端设置和安全策略。
为了有效解决这些问题,需要进行系统故障排除、分析日志、优化网络和服务器配置,并根据业务需求选择合适的链路和带宽。对于企业级应用,还应该建立监控和告警机制,防范潜在风险,确保远程管理和业务运营的连续性。
301重定向是一种HTTP状态码,表示请求的资源已经永久移动到了新的位置。在网站服务器上设置301重定向,可以将一个链接永久性的转移到另一个页面链接。下文将为大家详细介绍下网站服务器设置301重定向的教程,仅供参考。
文章目录搭建网站最重要的事情就是要拥有一款合适的网站服务器,热门网站服务器提供商有、BlueHost、阿里云等,下面一起来了解下。
1、Hostinger虚拟主机Hostinger虚拟主机提供Premium、Business、Cloud Startup三种方案可选,25GB-100NVMe存储、25-100建站个数、免费SSL证书、免费域名,价格低至$2.99/月起。
Hostinger官网:
2、BlueHost虚拟主机虚拟主机提供Basic、Choice Plus、eCommerce Premium三种方案可选,10GB-100 SSD存储、10-100网站、免费CDN、免费域名,价格低至$1.99/月起。
BlueHost官网:
3、阿里云虚拟主机阿里云虚拟主机是一种网站托管服务,预装了常见网站开发语言的运行环境、数据库及管理工具,用户可以通过图形化控制面板便捷地管理托管网站。
阿里云官网:
如何使用RDP远程连接?有多种方法可以通过Windows PC或MAC连接到Windows服务器。默认选项是通过捆绑到 Windows PC 中的 Windows 远程桌面连接 (RDP),或者可以安装第三方软件,例如 mRemoteNG 或 Parallels Client。
文章目录简单的方法是搜索远程桌面连接,或者打开命令提示符并键入:mstsc或通过转到 C:\Windows\System22\mstsc.exe。
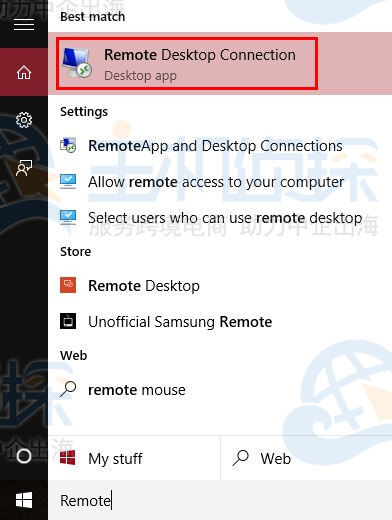
找到 RDP 打开远程桌面连接后,在“计算机”字段中输入 IP 地址,然后单击“连接”,用户名是管理员,系统将提示输入密码。
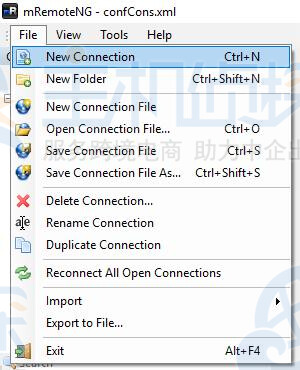
RDP远程连接Windows服务器方法二:mRemoteNG另一种选择是使用 mRemoteNG,这是一款用于远程连接的软件,是一种更现代的 Windows VPS 管理方式,具有选项卡、自动重新连接和屏幕大小调整功能。
安装后,只需转到文件-新连接。
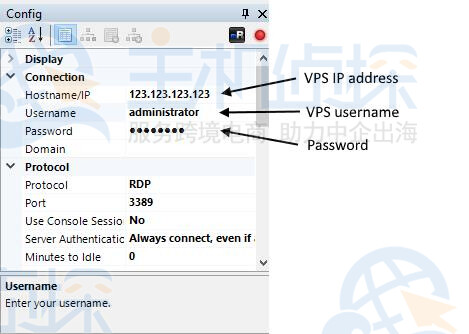
然后需要在左下角输入VPS的详细信息,这些详细信息可以在 VPS 信息电子邮件或客户区中找到。
还可以下载 Parallels 客户端以连接到 Windows VPS,安装后,只需转到“新建连接”,然后选择“标准 RDP”,然后输入凭据。
RDP远程连接Windows服务器方法四:MAC电脑若要通过 MAC 连接,请转到 App Store 并下载 Microsoft 远程桌面。
Gogs(Go Git Service)是一款基于Go语言精心开发的开源Git服务。它最大的特点就是轻量化、低资源消耗,旨在为用户提供一个自托管的Git仓库管理平台。Gogs拥有极简的界面设计,操作简单直观,即使是初次使用的开发者也能快速上手。而且,它对硬件的要求极低,最低仅需512MB内存就能稳定运行,这使得它尤其适合个人开发者、小型团队,或者那些对服务器资源较为敏感的场景使用。本文就为大家介绍如何通过宝塔面板的Docker模块,快速部署一款轻量级的开源Git服务Gogs。
文章目录宝塔面板官网:
宝塔面板提供了便捷的Docker管理功能。首先打开宝塔面板,在左侧菜单栏中找到“Docker”选项并点击进入。在Docker管理界面,搜索框中输入“gogs”,然后点击搜索按钮。在搜索结果中找到Gogs的镜像,点击“安装”按钮,就会自动开始下载并安装Gogs。整个过程无需复杂的配置,等待安装完成即可。
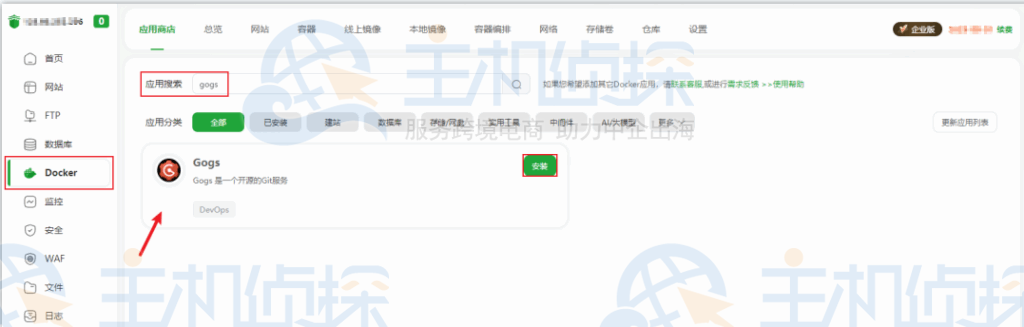
安装完成后,接下来就可以访问Gogs了。打开浏览器,在地址栏中输入“浏览器IP + 端口号”(这里的端口号默认是3000,如果你在安装过程中修改了端口号,就输入你修改后的端口号),然后按下回车键。这时就能看到Gogs的安装界面了。
3、运行配置Gogs首次运行Gogs安装程序时,需要创建Gogs数据库,并完成Gogs的配置。你需要填写数据库信息和Gogs的基本信息。数据库信息包括数据库类型(如MySQL、SQLite等)、数据库地址、用户名、密码等;Gogs基本信息则包括站点名称、域名、仓库存储路径等。这些配置信息填写完成后,点击“安装”按钮,Gogs就会根据配置进行初始化安装。

安装完成后,会跳转到登录页面。由于是首次使用需要创建一个管理员账号。填写好用户名、密码、邮箱等信息后,点击“注册”按钮,这个账号就成为了Gogs的管理员账号。通过管理员账号可以对Gogs进行各种管理操作,如用户管理、仓库管理等。
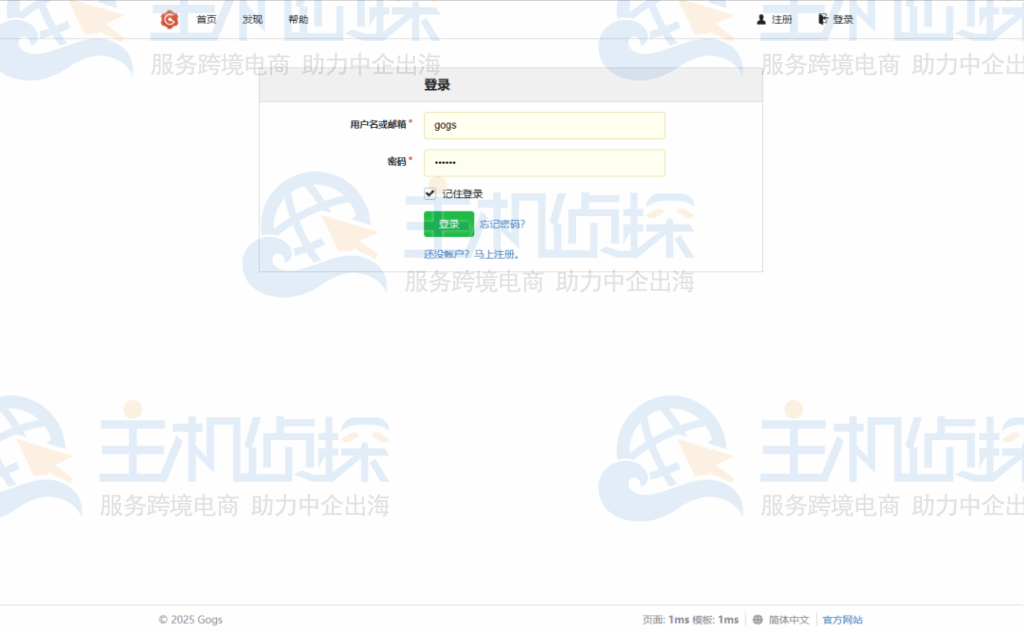
完成上述步骤后就可以开始使用Gogs创建自己的仓库了。登录Gogs后,在页面中找到“创建仓库”的按钮并点击。在弹出的仓库创建页面中,填写仓库的名称、描述等信息,还可以选择仓库是公开还是私有。填写完成后,点击“创建仓库”按钮,这样一个全新的仓库就创建成功了。
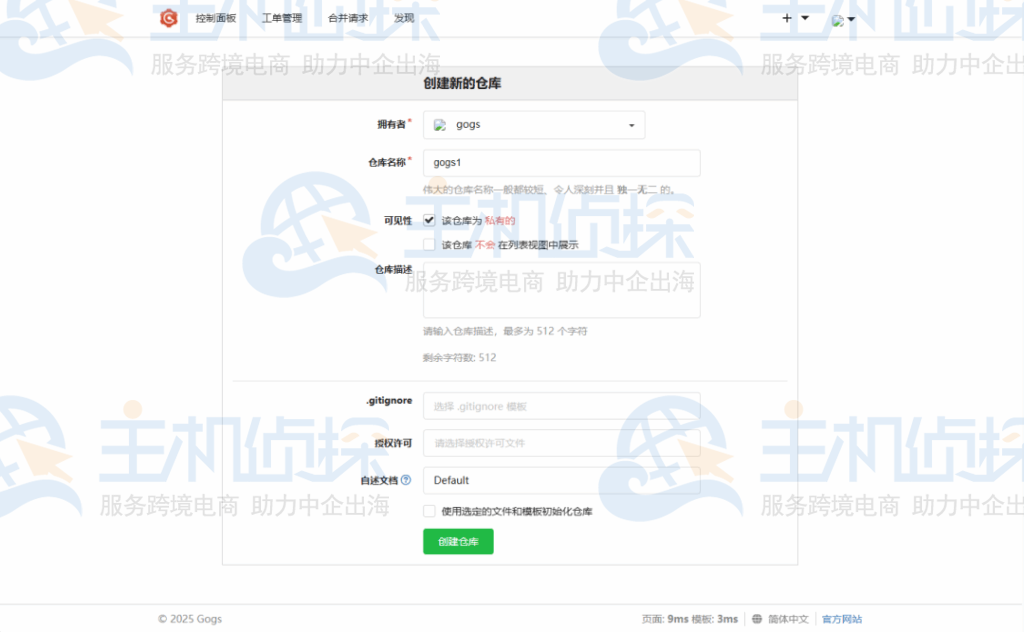
Xftp 8是干什么的? 8是一个功能强大但轻量级的SFTP/FTP客户机,用于需要在网络上安全地传输文件的用户;通过使用 拖放、直接编辑、增强的同步、传输调度和更直观的选项卡界面等特性,文件传输得到了简化。
Xftp 8下载:
Xftp 8支持主机之间的拖放,因此可以轻松地可视化文件/文件夹的移动;可以检查传输窗口,以查看所有传输的进度,并查看队列中有什么。根据需要暂停和恢复文件传输。
2、Xftp安全和高效在不断变化的网络环境中,采取必要的预防措施来保护您的数据是很重要的。Xshell 8支持RSA/DSA/ECDSA/ED25516公钥,密码和键盘交互,GSSAPI,和PKCS#11身份验证。使用不断更新的加密算法列表加密您的流量,并使用的主密码特性在云中安全存储会话文件。
3、Xftp便捷管理Xftp 8使管理会话比以往任何时候都更容易。不管是在2台主机上工作还是在200台主机上工作,优化工作流的特性,比如标签环境、直接编辑、同步导航等等。
二、Xftp 8特点 1、Xftp文件传输调度Xftp 8现在允许根据用户定义的时间表发送和接收文件。设置时间表,并让Xftp处理其余的工作。
2、Xftp可继承的会话属性会话文件夹现在可以作为在其下创建的任何新会话的模板,还可以将对会话文件夹所做的更改应用到已存在的会话和子文件夹。如果需要创建具有类似属性的多个会话文件,或者在需要大量编辑多个会话文件时,此特性可能非常有用。
3、Xftp文件快速搜索使用Xftp 8的快速文件搜索,可以轻松地搜索和过滤当前目录的文件和 子目录。当需要快速搜索要传输、删除的文件和目录时,这个功能可以派上用场。
4、Xftp图片缩略图预览使用Xftp 8可以直接在Xftp中查看图像文件的缩略图预览。不要只通过名称来识别图像文件,要确定正在编辑/传输的图像。
5、Xftp增强同步Xftp 8增强了本地和远程多个文件的同步能力。用户可以轻松地将其本地工作同步到远程或备份服务器,以创建一致的环境。
工具顺手免费又好用,是大部分网站管理员的必备软件,今天就互联网上大家问的最多的问题“PuTTY远程连接SSH”进行详细步骤拆解演示,细分为Windows和Linux系统,大家各自认领跟着操作吧!
文章目录PuTTY是个免费开源的SSH客户端,Windows和UNIX系统都能轻松使用,轻松连到开启了SSH服务的服务器,操作起来简单方便,类似于直接在远程服务器的控制台操作。
1、安装PuTTY并连远程主机
先访问PuTTY官网下载PuTTY安装程序,运行安装好后打开,会看到配置菜单。
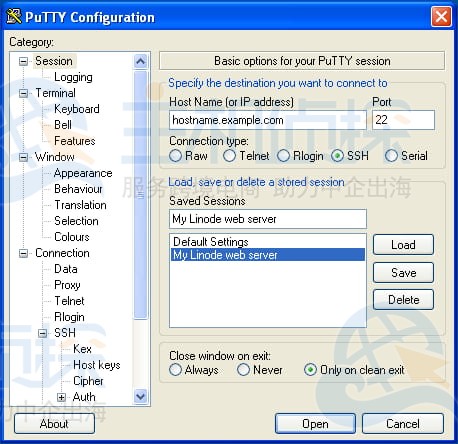
在“会话”类别里,填上远程主机(例如用的是或者BlueHost主机,直接在主机后台获取)的主机名或IP地址。SSH默认端口是22,如若服务器的SSH用了别的端口,也需要填写对应数据。
填完点“打开”启动SSH会话。第一次用PuTTY登系统会弹出个消息,提示服务器的SSH密钥指纹是新的,记得先验证指纹再点击继续。
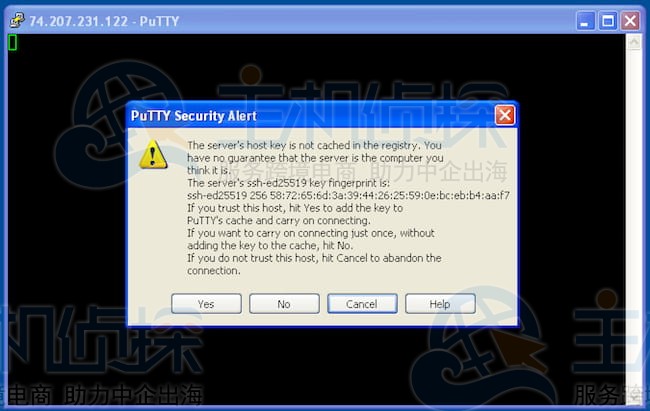
使用以下命令查询OpenSSH以获取主机的SSH指纹:
ssh-keygen -E md5 -lf /etc/ssh/ssh_host_ed25519_key.pub
就能查到主机的SSH指纹。类似于一下输出:
256 MD5:58:72:65:6d:3a:39:44:26:25:59:0e:bc:eb:b4:aa:f7 root@localhost (ED25519)
如果想查RSA密钥的指纹,需要用以下命令:
ssh-keygen -lf /etc/ssh/ssh_host_rsa_key.pub
记得将上面查到的指纹和PuTTY弹出的警报里的指纹对比一下,需要一直才行。如果指纹对上了即可点击“是”连你的主机,指纹会被保存起来。
如若出现指纹对不上的情况请避免继续连接,一般只有重装远程服务器系统时,密钥才会变。如果之前存过主机密钥,现在又弹出这警告,连接就不可信了。
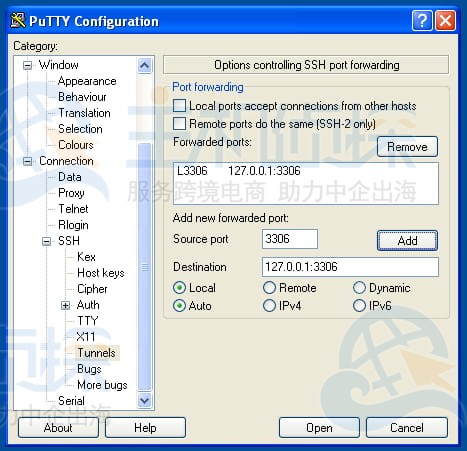
2、用PuTTY端口转发
SSH能让你通过安全通道访问远程服务器上的网络服务。比如有些服务未开,或者不想让外人访问,用这个就很合适。举个例子,能通过SSH安全访问远程的MySQL服务器,步骤如下:
如此设置后,本地的MySQL客户端直接连localhost:3306。你和远程MySQL服务器的连接会被SSH加密,不用让MySQL暴露在公网也能访问。
二、Linux系统用PuTTY远程登录SSH图文教程Linux常当服务器用,因这些服务器一般放机房,无法直接上手操作,所以需要远程登录管理操作。Linux的远程登录依靠SSH服务,默认端口22。Windows上能远程登Linux的客户端不少,这里还是说PuTTY。
1、基本登录步骤
和上面的首要步骤一样,PuTTY官网下载好PuTTY,双击putty.exe打开。
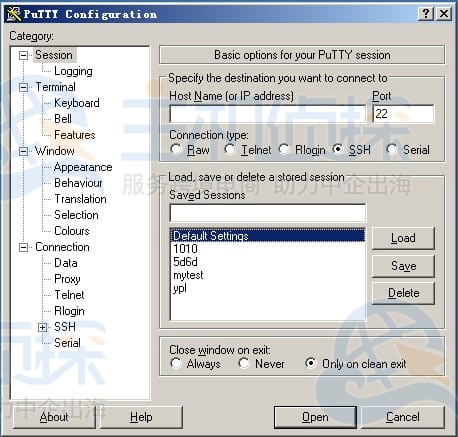
在弹出窗口的“Host Name(or IP address)”框里,输入远程服务器的IP(服务器上用ifconfig能查到),回车。
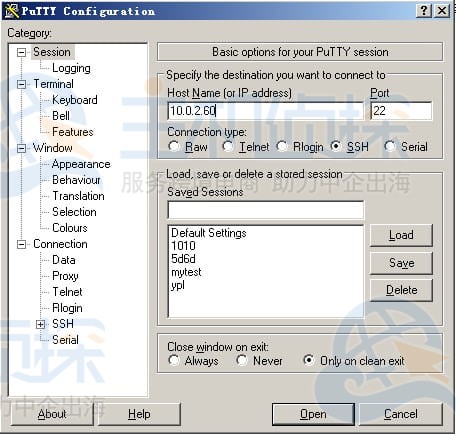
之后会让你输登录用户名,输入root回车,再填写密码即可登进远程Linux系统。
2、用密钥认证远程登录
SSH是应用层和传输层上的安全协议,用密钥认证登录更安全,步骤如下:

生成密钥对:打开PUTTYGEN.EXE,默认用SSH-2(RSA),“Number of bits in a generated key”填2048(数值越大,密钥越复杂,越安全)。点击“Generate”开始生成,过程中记得多动动鼠标,不然进度条不动。
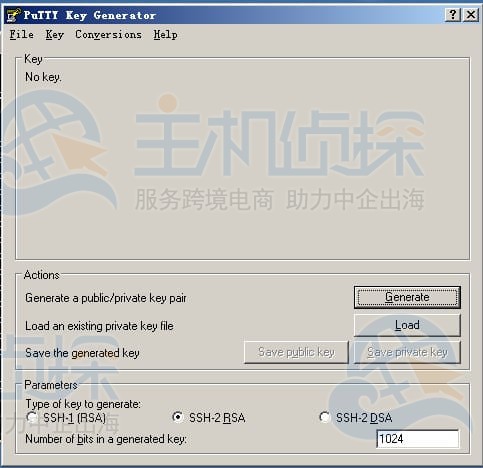


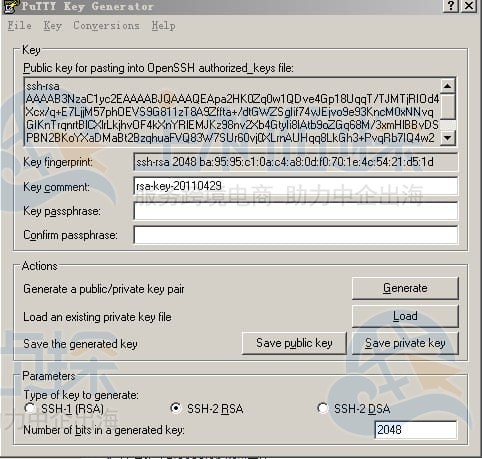
密钥生成后,能在“Key Passphrase”设个密码(建议设,更安全),然后点“Save public key”存公钥,“SaveprivateKey”存私钥,放个安全的地方,别让人偷看或误删。
配置远程Linux主机:
登远程Linux,建个/root/.ssh目录,输[root@localhost~]#mkdir/root/.ssh,再用[root@localhost~]#chmod700/root/.ssh设权限。
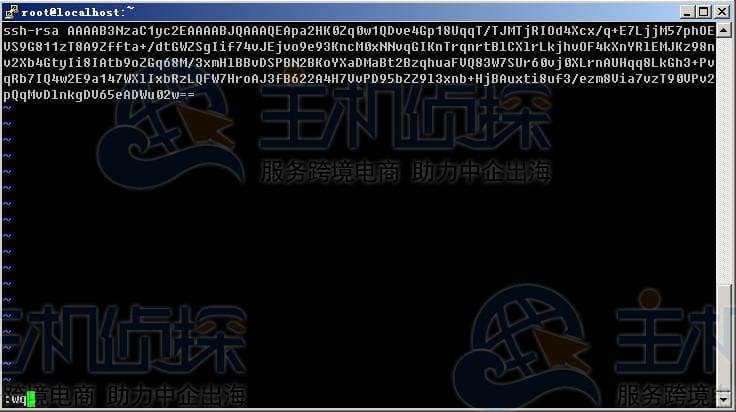
用[root@localhost~]#vim/root/.ssh/authorized_keys建这个文件。打开之前存的公钥文件(用写字板打开看着清楚),复制从AAAA开头到“—-ENDSSH2PUBLICKEY—-”那行的所有内容整理成一行(可以先粘到记事本里整理好)。
用vim打开authorized_keys后(文件不存在的话vim会自动建),按“i”进入编辑模式,粘进去,然后在最前面输“ssh-rsa”(后面带个空格)。按ESC,输“:wq”保存退出。
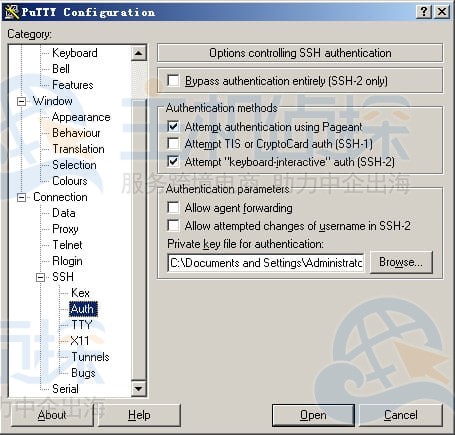
然后设置PuTTY:点左侧的“SSh–>Auth”,点右侧“Browse…”选刚才存的私钥,再点“Open”。这时输入root直接登陆,如若之前设了Key Passphrase则需要输入密码。
Node.js是一个高可扩展性的开源跨平台JavaScript 运行环境,采用事件驱动的无阻塞 /0 设计,具有轻量高效的运行优势。有时候用户为了构建一些实时应用程序,微服务架构或者是开发API,会疑惑Nodejs到底安装及配置的?大多数情况下一些商都是不支持安装Node.js的。
所以本文将围绕该问题,从0开始开始解释Nodejs是什么,之后解答如何安装及使用cPanel和命令行配置Nodejs的详细内容,以供大家参考。
文章目录Node.js是一个开源、跨平台(Windows、macOS 和 Linux)的后端JavaScript 运行环境,V8 引擎上运行,并在 Web 浏览器之外执行 JavaScript 代码。
其主要优势之一便是其异步、非阻塞架构,可以处理许多并发连接并执行多个任务,而无需等待一个任务完成后再继续执行下一个任务,因此Node.js 可广泛用于构建可扩展的网络应用程序,尤其是聊天应用程序、在线游戏和协作工具等实时应用程序。
Node.js还支持以下应用场景:
快速执行:其非阻塞架构和事件驱动模型可实现快速执行任务,使其适用于高流量应用程序。
庞大的生态系统:npm 注册表提供对各种预构建包和库的访问。
跨平台:Node.js 兼容多种作系统,简化部署。
活跃的社区:Node.js 拥有庞大而活跃的开发人员社区,这意味着广泛的文档和支持。
2、Node.js 缺点单线程:虽然 Node.js 的单线程事件循环对于许多任务都很有效,但对于需要大量CPU计算的任务来说,拥有专用资源的可能比Node.js主机更好。。
回调困难:在大型应用程序中,管理回调和处理异步代码可能会变得复杂,然而现代 JavaScript 以及 Promise 和 async/await 的使用缓解了这个问题。
二、如何为网站安装Node.js对于想要为自己网站安装Node.js,最简单且便捷的方法便是通过Node.js托管,托管商托管通过提供支持部署和执行Node.js应用程序的平台和基础设施,实现对Node.js 应用程序的优化。
以下是有关Node.js托管需要考虑的一些关键点:
1、Node.js兼容性:Node.js托管方案被配置与 Node.js 无缝协作,因此需要提供必要的运行时环境,允许商家部署和运行Node.js应用程序,而不会出现兼容性问题。
2、性能:Node.js托管提供商通常使用针对 Node.js 应用程序优化的服务器配置,提高性能并更快地执行 Node.js 代码。
3、可扩展性:考虑提供可扩展性选项的Node.js托管服务,使用户能够随着流量和用户群的增长轻松扩展应用程序。这种可伸缩性对于处理增加的负载和保持良好的性能至关重要。
4、部署工具:Node.js托管平台应该提供部署工具和集成,以简化上传和管理 Node.js 应用程序的过程。这些工具可能包括 Git 集成、自动部署和轻松扩展选项。
5、支持 Node Package Manager (npm):Node.js托管服务要附带对 npm(Node 包管理器)的内置支持,这样可以更加方便地为应用程序管理和安装第三方软件包和库。
6、负载平衡和高可用性:考虑提供负载平衡和高可用性功能的Node.js托管服务提供商,以确保应用程序即使在流量高峰或服务器故障期间也能保持可访问性和响应能力。
7、数据库和后端服务:Node.js托管平台要提供集成数据库和后端服务,有利于简化数据库设置、缓存和应用程序所需的其他组件的过程。
8、安全:Node.js托管服务提供商提供包括 DDoS 保护、防火墙配置和定期安全更新等安全功能,以保护应用程序。
9、技术支持:信誉良好的 Node.js 托管服务会提供技术支持,以解决与 Node.js 应用程序或托管环境相关的任何问题。
10、成本:Node.js托管计划在定价方面各不相同,因此在选择托管服务提供商时考虑预算和要求非常重要。
为了方便大家更快更便捷的购买到符合以上要求的Node.js主机托管方案,小编推荐 Node.js主机托管。
原因无他,无论是从价格、性能、安全性,还是从Node.js兼容性、服务技术支持,ChemiCloud国外主机商都为用户提供了最佳的购买性价比,在保障每月2.5美元低廉价格的同时,又提供了低延迟、高安全、100%网络正常运行时间的保障。
ChemiCloud官网:
(1)创建应用程序
登录 cPanel,在 cPanel 的“软件”部分,单击“设置Node.js应用程序”图标。

在Node.js选择器页面上,单击“创建应用程序”按钮以开始应用程序设置。

填写应用程序设置表单上的必填字段。
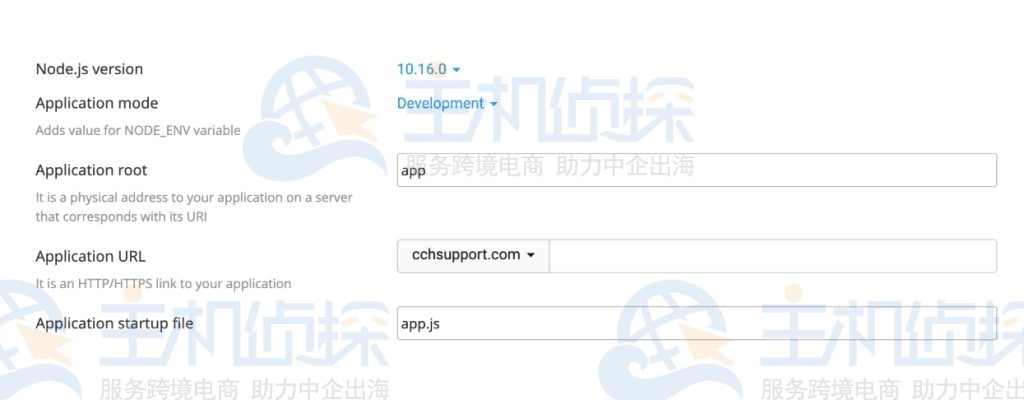
表单完成后,单击“创建”按钮。创建应用程序后,会显示一个信息框,提示需要package.json才能继续。

应用程序将启动并显示一个测试页面,如果要查看测试页是否正常工作,请单击 Open 按钮,点击取消按钮继续。
现在已安装一个有效的应用程序,可以使用 package.json 设置文件和 npm 包管理器来增强环境。要安装 package.json 和 npm,请按照接下来两节中的步骤作。
(2)创建包 JSON
返回 的仪表板。在 cPanel 的“文件”部分,单击“文件管理器”图标以打开“文件管理器”。

在 File Manager(文件管理器)的左侧列中,单击应用程序根文件夹的文本。
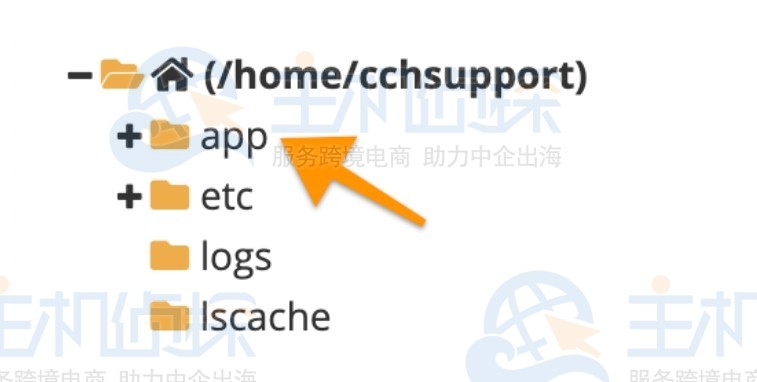
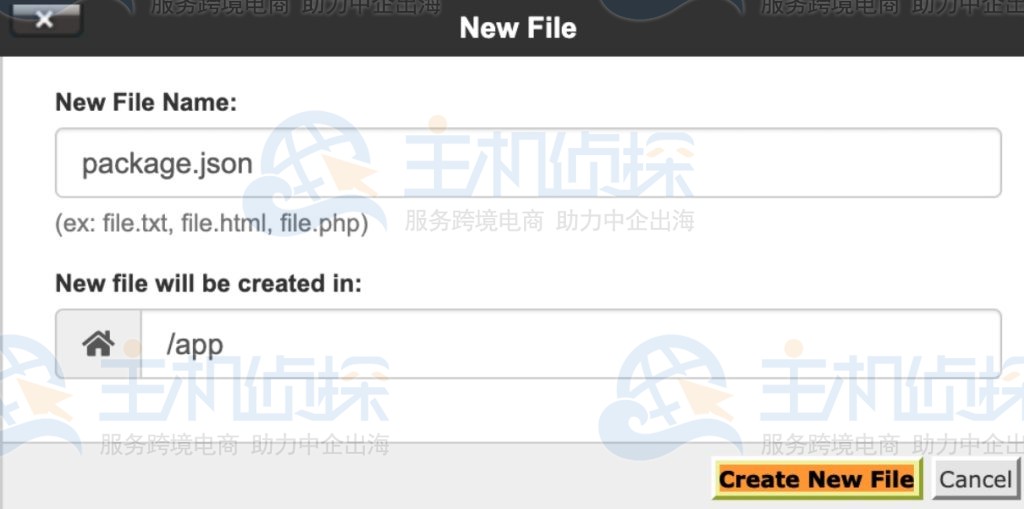
单击 +File 按钮创建新文件,在 New File 对话框中,输入 file name package.json然后单击 Create New File 按钮。
创建文件后,右键单击或辅助单击文件管理器右侧栏中的package.json文件,然后单击编辑,此时将显示一个编辑对话框。
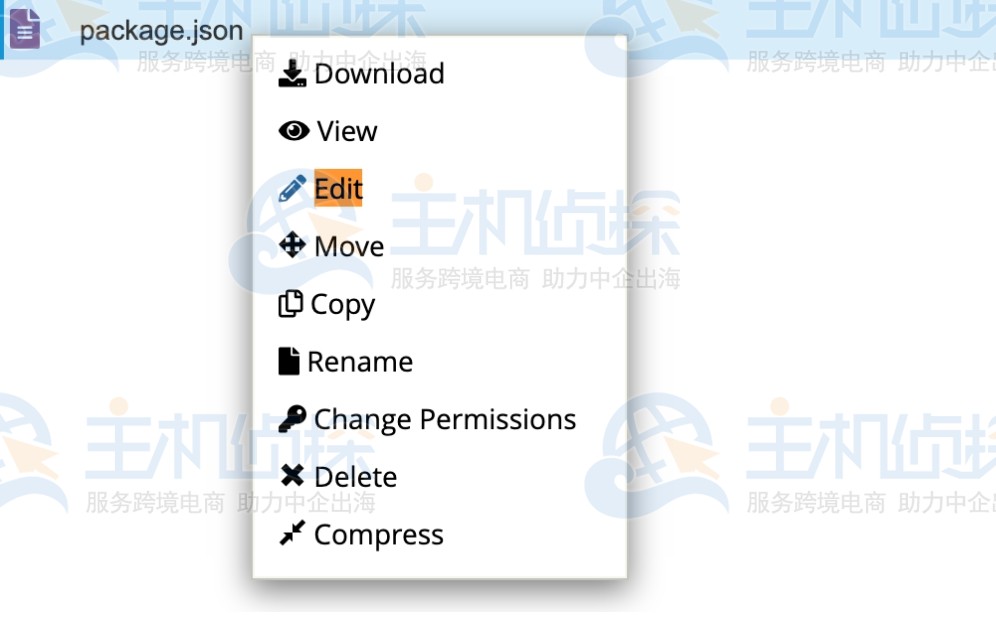
在编辑对话框中,单击 OK 按钮并在编辑器屏幕中输入以下文本,之后点击保存更改按钮保存文件,并单击“关闭”按钮以关闭编辑器。
{
"name": "app",
"version": "1.0.0",
"description": "My App",
"main": "app.js",
"scripts": {
"test": "echo \"Error: no test specified\" && exit 1"
},
"author": "",
"license": "ISC"
}
(3)安装 NPM
在 cPanel 的“软件”部分,单击“设置Node.js应用程序”图标。

在 Web 应用程序列表的 Actions 列中,单击铅笔图标以编辑应用程序。
单击 Run NPM Install 按钮,之后NPM安装过程将运行,并在完成后显示以下内容:

要使用 NPM 安装软件包并执行与应用程序相关的其他命令行任务,请通过 SSH 登录,然后使用应用程序设置页面顶部信息框中显示的命令进入应用程序的虚拟环境。

如果熟悉使用 SSH,可能会发现命令行界面比使用 cPanel 安装界面更快、更容易。要从命令行设置 node.js 应用程序,请执行以下步骤:
通过 SSH 连接到帐户,使用以下命令创建 Node.js 应用程序:
cloudlinux-selector create --json --interpreter nodejs --version 11 --app-root app --domain example.com --app -uri app
进入帐户的主目录后,切换到应用程序目录。
cd ~/app
打开首选的文本编辑器并创建 package.json 文件,在本文中将使用 vi 编辑器。
vi package.json
按 I 键更改为 Insert 模式,并将以下文本粘贴到编辑器中。按 Escape 键,然后按 : 进入命令模式;按 x 然后按 Enter 键保存并退出 vi 编辑器。
{
"name": "app",
"version": "1.0.0",
"description": "My App",
"main": "app.js",
"scripts": {
"test": "echo \"Error: no test specified\" && exit 1"
},
"author": "",
"license": "ISC"
}
输入以下命令安装 npm。
cloudlinux-selector install-modules --json --interpreter nodejs --user example --app-root app
要使用 NPM 安装软件包并执行与应用程序相关的其他命令行任务,请通过 SSH 登录并使用命令。
source /home/example/nodevenv/app/11/bin/activate && cd /home/example/app

 samly
samly


