在Linux上搭建Hadoop的高可用性(HA)主要涉及NameNode与ResourceManager的高可用配置、借助ZooKeeper监控状态及执行故障切换、以及制定数据备份与恢复计划。以下是具体步骤:
1. 准备工作
- :建议选用CentOS 7或Ubuntu 20.04。
- Java版本:需安装JDK 8。
- 网络配置:保证各节点具备固定IP地址,并完成主机名及DNS设置。
2. Hadoop安装
- 下载并解压Hadoop安装包至指定路径。
- 设置环境变量,例如 HADOOP_HOME 和 JAVA_HOME。
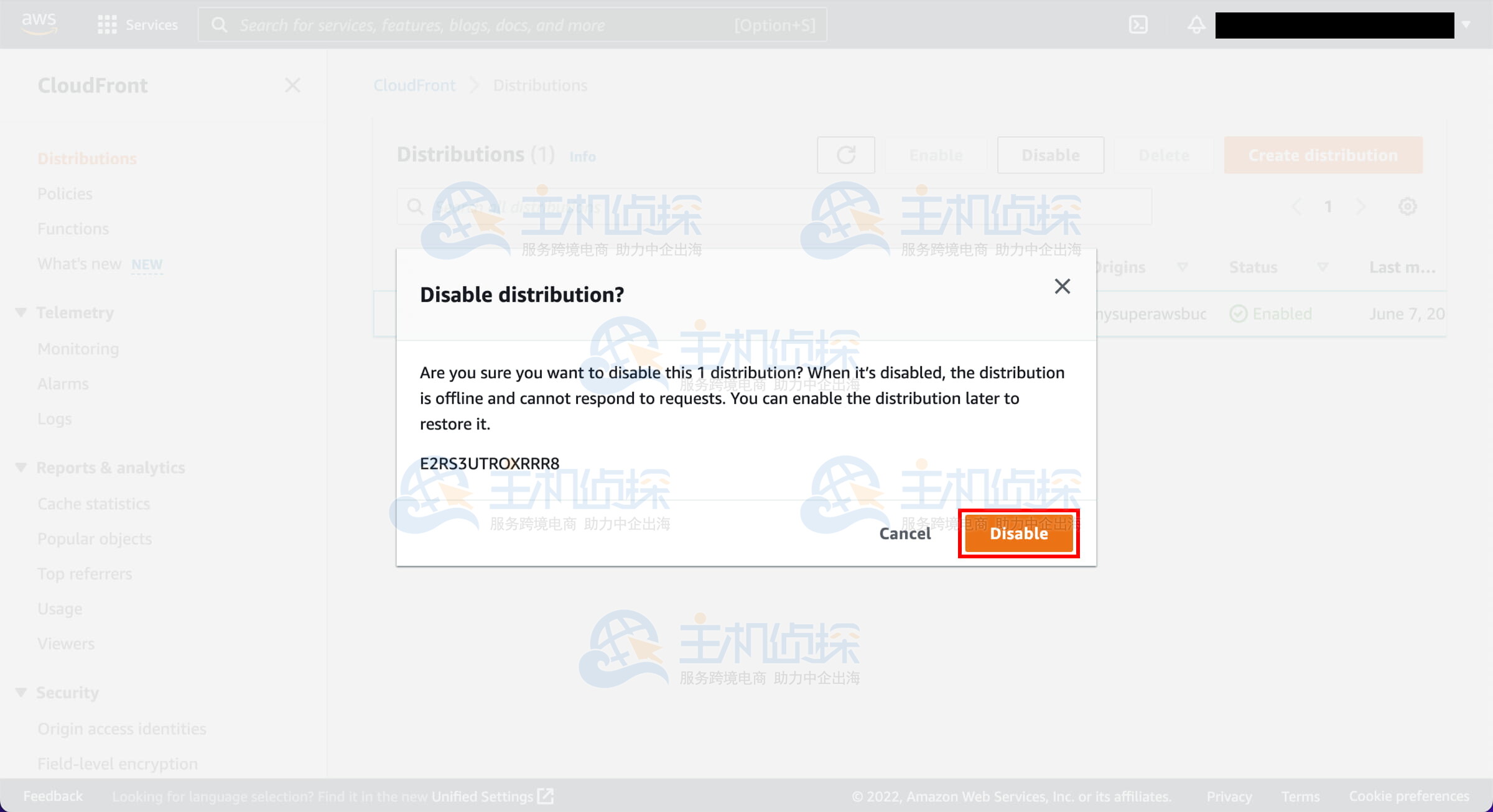
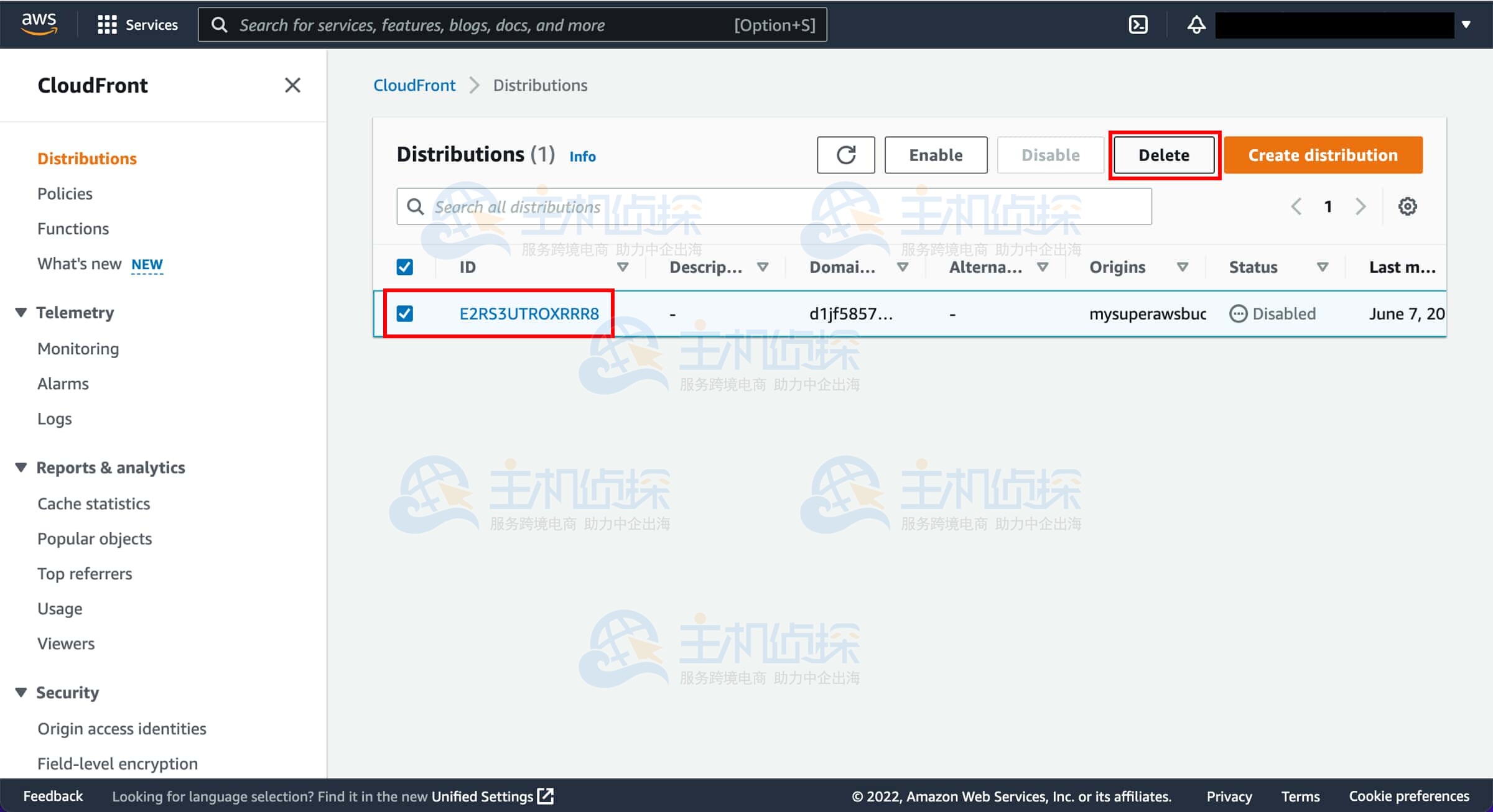
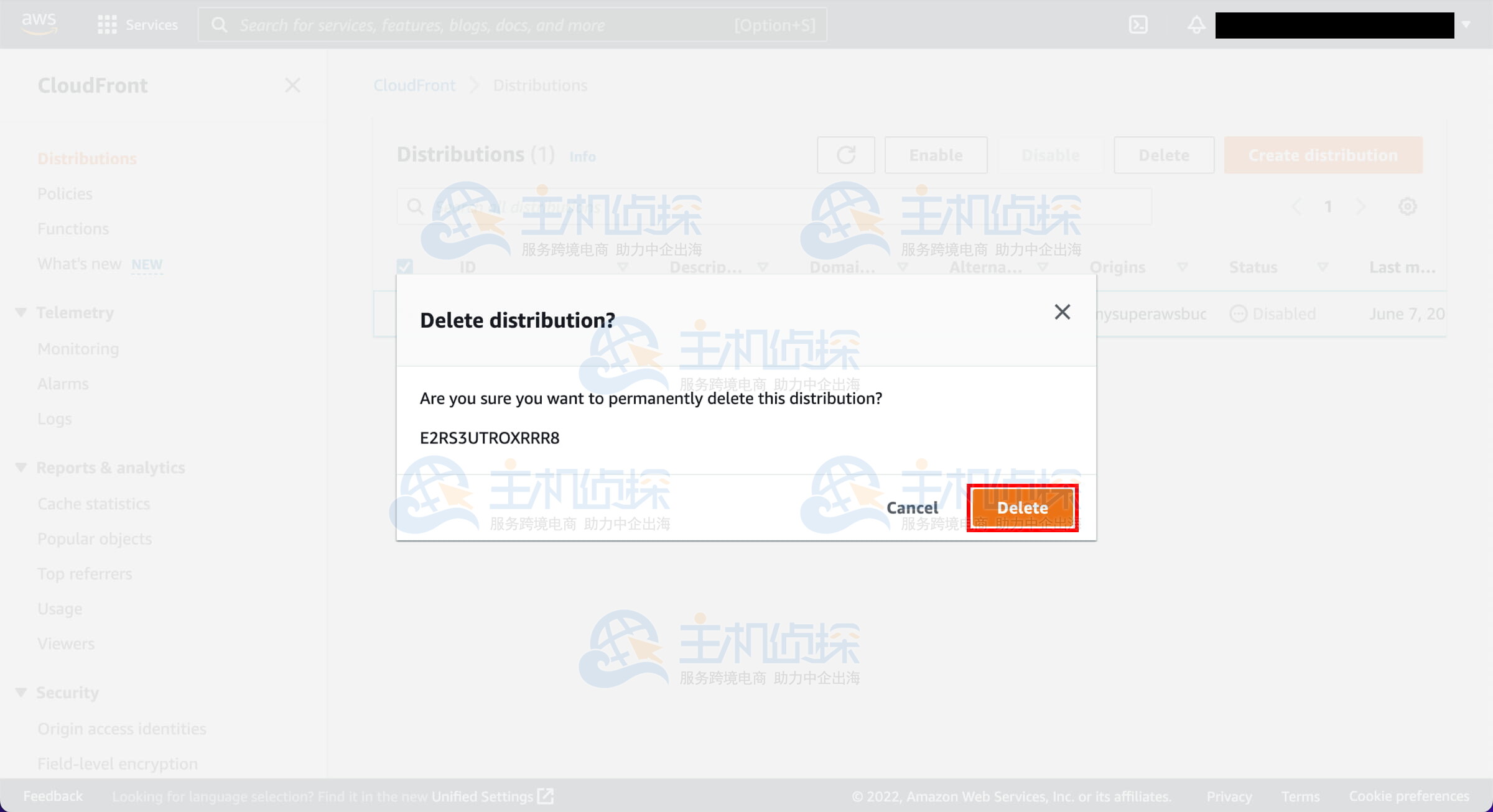
3. 高可用性配置
NameNode高可用性
- 主备模式:设定两个NameNode,其中一个为Active状态负责处理客户端请求,另一个为Standby状态充当热备份。
- 共享存储系统:利用NFS或HDFS本身同步NameNode的元数据信息。
- ZooKeeper集群:构建ZooKeeper集群以跟踪NameNode的状态,在主节点失效时触发自动切换。
- 故障转移方案:借助ZooKeeper和ZKFloverController(ZKFC)实现自动故障转移。
ResourceManager高可用性
- 设定主ResourceManager与备用ResourceManager。
- 在 yarn-site.xml 文件中启用 yarn.resourcemanager.ha.enabled 和 yarn.resourcemanager.cluster-id 等参数。
其他优化建议
- 数据备份与恢复策略:定期对HDFS数据进行备份,确保紧急情况下能迅速恢复。
- 监控与报警配置:采用Ganglia、Prometheus等监控集群状况,建立报警机制。
- 性能提升措施:如数据压缩、资源合理分配、网络调整等。
4. 启动Hadoop集群
- 初始化NameNode。
- 开启HDFS和YARN服务。
5. 测试高可用性
- 运行 jps 命令确认NameNode和ResourceManager运行无误。
- 模拟节点故障,检查自动切换功能是否有效。
上述内容概括了在Linux环境下配置Hadoop高可用的基本方法。依据实际需求和具体情况,或许还需进一步调整和改进配置。
AI在线配音生成器

66








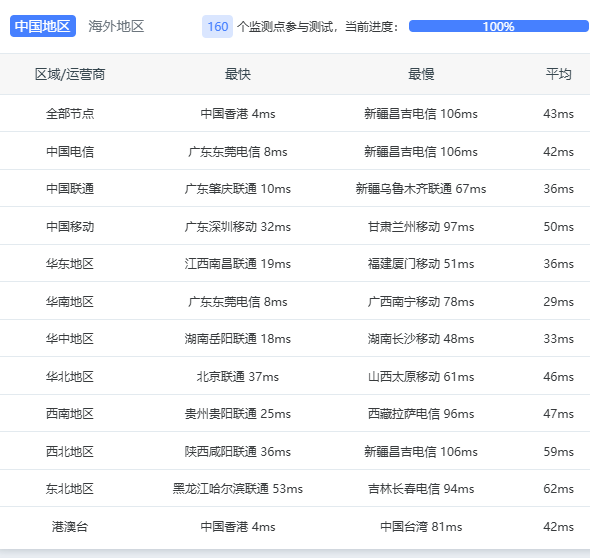 回国线路平均40ms左右,三网直连高峰期不跳线路!
回国线路平均40ms左右,三网直连高峰期不跳线路!