中的join类型包括inner join、left join、right join、full join和cross join,它们在数据关联方式和性能上存在显著差异。inner join仅返回两表匹配的行,性能最优;left join保留左表所有行,右表无匹配时填充null,性能开销较大;right join与left join类似但以右表为基准,使用较少;full join返回两表所有行,需通过left join与right join组合模拟,性能复杂度高;cross join生成笛卡尔积,结果集巨大,性能消耗极高。选择正确的join类型不仅影响数据准确性,还直接影响查询效率、资源消耗和系统稳定性。优化策略包括建立索引、先过滤再join、避免、仅选择必要列、合理使用expln分析执行计划。此外,在 text中可通过语法高亮、多光标编辑、自定义代码片段和格式化提升sql编写效率。

理解MySQL中的JOIN类型及其性能差异,对于编写高效、准确的数据库查询至关重要。这不仅仅是语法层面的掌握,更是对数据如何关联、如何被数据库引擎处理的深层理解。选择正确的JOIN类型,并辅以恰当的优化策略,能够显著提升查询速度,减少资源消耗,尤其是在处理大规模数据时,这种差异会被无限放大。而在像Sublime Text这样的编辑器中,虽然它本身不执行SQL,但其强大的编辑功能,如语法高亮、多光标和自定义代码片段,能极大地提升我们编写和管理这些复杂查询的效率。

MySQL JOIN类型与性能对比分析
在MySQL里,我们日常打交道最多的就是各种JOIN操作了。它们是连接不同表,从多个数据源获取完整信息的核心手段。但说实话,每种JOIN类型背后的逻辑和对性能的影响,有时候真的能让人头疼,尤其是当数据量上来之后。
INNER JOIN(内连接) 这是最常见的连接方式,它只返回两个表中都有匹配的行。你可以把它想象成两个集合的交集。从性能角度看,INNER JOIN通常是最快的,因为它的结果集最小,数据库引擎不需要处理不匹配的数据。如果JOIN条件上的列都建立了索引,那么查询速度会非常惊人。我个人在使用时,如果确定只需要匹配的数据,总是首选INNER JOIN,因为它最“纯粹”,意图也最明确。

示例:
SELECT
o.order_id,
c.customer_name
FROM
orders o
INNER JOIN
customers c ON o.customer_id = c.customer_id;
LEFT JOIN / LEFT OUTER JOIN(左连接) 左连接会返回左表中的所有行,以及右表中与左表匹配的行。如果右表中没有匹配的行,则右表对应的列会显示为NULL。这个操作在需要保留“主”表所有信息,并尝试从“副”表获取额外数据时非常有用。但它的性能开销通常比INNER JOIN大,因为它必须扫描左表的所有行,并为每一行去右表寻找匹配。如果右表非常大,并且没有合适的索引,那么性能问题会立刻显现。

示例:
SELECT
c.customer_name,
o.order_id
FROM
customers c
LEFT JOIN
orders o ON c.customer_id = o.customer_id;
(这里会列出所有客户,即使他们没有下过订单)
RIGHT JOIN / RIGHT OUTER JOIN(右连接) 右连接与左连接类似,但它是以右表为基准,返回右表中的所有行,以及左表中匹配的行。如果左表中没有匹配,则左表对应的列为NULL。在实际开发中,RIGHT JOIN用得相对较少,因为大多数情况下,RIGHT JOIN都可以通过交换表的位置,转换成LEFT JOIN来表达,这样更符合从左到右的阅读习惯。
示例:
SELECT
c.customer_name,
o.order_id
FROM
orders o
RIGHT JOIN
customers c ON o.customer_id = c.customer_id;
(效果与上面的LEFT JOIN示例类似,只是表的位置互换了)
FULL JOIN / FULL OUTER JOIN(全连接) 全连接会返回两个表中所有的行,无论它们是否匹配。如果某行在一个表中没有匹配,则另一个表的列会显示为NULL。MySQL本身并不直接支持 FULL OUTER JOIN 语法,这常常让人感到有些不便。我们通常需要通过 LEFT JOIN 和 RIGHT JOIN(或者说 LEFT JOIN 和 NOT EXISTS 或 UNION ALL)的组合来模拟实现。这种模拟方式,性能上会比直接的INNER JOIN复杂得多,因为它涉及到多个查询结果的合并和去重(如果使用 UNION 而不是 UNION ALL)。
模拟示例(使用UNION ALL):
标书对比王是一款标书查重工具,支持多份投标文件两两相互比对,重复内容高亮标记,可快速定位重复内容原文所在位置,并可导出比对报告。

12
SELECT
c.customer_name,
o.order_id
FROM
customers c
LEFT JOIN
orders o ON c.customer_id = o.customer_id
UNION ALL
SELECT
c.customer_name,
o.order_id
FROM
customers c
RIGHT JOIN
orders o ON c.customer_id = o.customer_id
WHERE
c.customer_id IS NULL; -- 这一部分是为了排除LEFT JOIN已经包含的匹配行
或者更常见的模拟方式,直接使用 LEFT JOIN 和 RIGHT JOIN 结合 UNION ALL,但要处理好重复:
-- 获取所有匹配的行 SELECT c.customer_name, o.order_id FROM customers c INNER JOIN orders o ON c.customer_id = o.customer_id UNION ALL -- 获取左表独有的行 SELECT c.customer_name, NULL FROM customers c LEFT JOIN orders o ON c.customer_id = o.customer_id WHERE o.order_id IS NULL UNION ALL -- 获取右表独有的行 SELECT NULL, o.order_id FROM customers c RIGHT JOIN orders o ON c.customer_id = o.customer_id WHERE c.customer_id IS NULL;
CROSS JOIN(交叉连接) 交叉连接会生成两个表的笛卡尔积,即左表中的每一行与右表中的每一行都进行组合。如果两个表各有N行和M行,结果集将有N*M行。这种操作在大多数业务场景下很少直接使用,因为它会产生巨大的结果集,性能开销非常大。通常只在需要生成所有可能的组合时(例如,测试数据生成、生成时间序列等)才会考虑。
示例:
SELECT
p.product_name,
s.store_name
FROM
products p
CROSS JOIN
stores s;
选择正确的JOIN类型如此关键?
说白了,选对JOIN类型,不光是为了拿到正确的数据,更是为了数据库能跑得更快,服务器少“喘气”。这背后的逻辑,我觉得主要有这么几点:
数据准确性是基石 这可能听起来是废话,但却是最容易被忽略的。如果你需要所有客户的信息,哪怕他们没下过单,却错误地用了 LEFT JOIN1,那你的结果集就直接“缺斤少两”了。反过来,如果只是想看有订单的客户,却用了 LEFT JOIN,虽然数据没错,但你可能要处理一堆 LEFT JOIN3 值,而且查询的资源消耗也会更高。所以,首先要明确你的业务需求,数据到底要怎么关联。
性能表现的巨大差异 这是最直观的感受。一个 LEFT JOIN1 可能几毫秒就跑完了,而一个设计不当的 LEFT JOIN 或者 LEFT JOIN6,在面对百万级甚至千万级数据时,可能让你等上几分钟,甚至直接拖垮数据库。
-
LEFT JOIN1 因为只返回匹配项,数据库可以更早地过滤掉不必要的行,优化器也更容易找到高效的执行路径,尤其是在连接字段有索引的情况下,效率非常高。 -
LEFT JOIN的挑战在于,它必须保证左表的所有行都被保留,这意味着即使右表没有匹配项,它也得“走一趟”。如果右表没有索引,或者连接条件不走索引,那每一次查找都可能变成全表扫描,效率自然就低了。 -
LEFT JOIN6 更不用说了,笛卡尔积意味着结果集呈指数级增长,内存和CPU的消耗都是巨大的,稍不留神就能让你的数据库“宕机”。
资源消耗与系统稳定性 错误的JOIN类型会导致查询消耗更多的CPU、内存和I/O资源。想象一下,一个本来只需要几MB内存的查询,因为一个不合理的 LEFT JOIN6 变成了几GB,这很快就会耗尽服务器资源,影响其他正常运行的查询,甚至导致整个数据库服务不稳定。尤其是在高并发的生产环境中,一个慢查询就可能引发连锁反应。我们总是希望用最少的资源,做最多的事。
可维护性与代码意图清晰 当我看到一段SQL,如果JOIN类型选择得当,我能一眼看出作者的意图:是需要所有左边的数据,还是只关心匹配的部分。这对于团队协作和后续的代码维护至关重要。一个模糊不清的JOIN,往往意味着背后的业务逻辑也不够清晰,或者说,作者对JOIN的理解还不够深入。
在Sublime Text中编写和优化JOIN查询的实践技巧
Sublime Text本身不是数据库客户端,但它作为一个强大的文本编辑器,在编写SQL查询方面,确实能提供不少便利,帮助我们提升效率,减少低级错误。
利用语法高亮和自动补全 Sublime Text安装相应的SQL语法包后(比如 RIGHT JOIN1 或 RIGHT JOIN2),会对SQL关键字、函数、字符串等进行高亮显示,这让代码的可读性大大提升。一眼就能看出哪个是关键字,哪个是表名或列名。此外,一些插件还提供了基本的自动补全功能,虽然不如专业IDE那么智能,但对于常用的SQL关键字和函数,也能节省不少敲击键盘的时间。
多光标编辑的妙用 这是Sublime Text的招牌功能之一,在编写JOIN查询时尤其有用。
- 批量添加表别名: 当你JOIN了多个表,想给它们都加上别名时,可以选中一个表名,然后使用
RIGHT JOIN3(Windows/Linux)或RIGHT JOIN4(macOS)选择所有相同的表名,然后同时输入别名,效率非常高。 - 快速修改JOIN条件: 如果你需要调整多个
RIGHT JOIN5 子句中的列名,或者批量修改RIGHT JOIN6 子句中的条件,多光标能让你同步操作,避免重复劳动和潜在的输入错误。
自定义代码片段(Snippets) 这是我个人觉得最能提升效率的功能之一。对于经常使用的JOIN模式,比如 LEFT JOIN1、LEFT JOIN 的基本结构,你可以创建自定义的Snippet。 例如,输入 RIGHT JOIN9 然后按 LEFT JOIN0 键,就能自动展开成:
INNER JOIN ${1:table_name} ON ${2:table1.column} = ${3:table2.column}$0
这里的 LEFT JOIN1 是占位符,你按 LEFT JOIN0 键就能快速跳转到下一个需要填写的位置。这不仅能减少输入,还能保证代码风格的一致性,减少因为拼写错误导致的语法问题。
格式化工具的辅助 虽然Sublime Text没有内置强大的SQL格式化功能,但可以通过安装插件(如 LEFT JOIN3 或 LEFT JOIN4)来实现。一个格式整齐的SQL查询,其可读性远高于一坨挤在一起的代码。尤其是在处理多表JOIN时,清晰的缩进和换行能帮助你快速理解每个JOIN的范围和条件,这对于后续的调试和优化是至关重要的。一个排版混乱的查询,往往也是一个难以维护和优化的查询。
常见JOIN性能陷阱与规避策略
在实际工作中,我们经常会遇到一些JOIN查询慢得让人抓狂的情况。这通常不是JOIN类型本身的问题,而是使用方式上掉进了“坑”里。
最大的陷阱:缺少索引 这几乎是所有慢查询的罪魁祸首,尤其是在JOIN操作中。如果JOIN条件中的列没有建立索引,那么数据库在执行JOIN时,很可能需要进行全表扫描(Full Table Scan)或者嵌套循环连接(Nested Loop Join),效率会非常低下。 规避策略: 确保所有用于JOIN的列都建立了合适的索引。通常是B-tree索引。对于 RIGHT JOIN5 子句中的列,以及 RIGHT JOIN6 子句中用于过滤的列,索引都是必不可少的。如果连接的列是复合索引的一部分,也要确保索引的顺序与查询条件匹配。
大表JOIN的挑战 当两个或多个非常大的表进行JOIN时,即使有索引,也可能因为需要处理的数据量过大而导致性能问题。 规避策略:
- 先过滤再JOIN: 尽可能在JOIN之前,使用
RIGHT JOIN6 子句对表进行过滤,减少参与JOIN的数据量。这比先JOIN再过滤要高效得多。 - 分批处理: 对于超大表的复杂JOIN,考虑将查询拆分成小块,分批处理,或者使用临时表(Temporary Table)来存储中间结果。
- 考虑数据冗余/反范式: 在某些极端情况下,为了性能,可能需要考虑在数据库设计层面进行适当的冗余,将经常JOIN的字段直接存储在同一个表中,以避免JOIN操作。这需要权衡数据一致性和性能。
WHERE子句与ON子句的微妙差异 在 LEFT JOIN 中,RIGHT JOIN6 子句和 RIGHT JOIN5 子句对结果的影响是不同的,这直接影响性能。
-
RIGHT JOIN5 子句在JOIN发生之前应用,它决定了哪些行会参与连接。 -
RIGHT JOIN6 子句在JOIN完成后才应用,它对整个结果集进行过滤。 规避策略: - 如果你想在JOIN之前就过滤右表的数据,从而减少JOIN的数据量,应该把过滤条件放在
RIGHT JOIN5 子句中。 - 如果你想在JOIN完成后对整个结果集进行过滤,那么条件应该放在
RIGHT JOIN6 子句中。 - 对于
LEFT JOIN1,RIGHT JOIN5 和RIGHT JOIN6 在过滤结果上通常没有,但从优化器的角度看,将过滤条件放在RIGHT JOIN5 子句中可能更有利于优化器提前进行过滤。
隐式类型转换 当JOIN条件中的列数据类型不一致时(例如,一个 NOT EXISTS9 类型列与一个 UNION ALL0 类型列进行JOIN),MySQL可能会进行隐式类型转换。这会导致索引失效,从而引发全表扫描。 规避策略: 确保JOIN条件中的列数据类型完全一致。这是数据库设计阶段就应该考虑的问题。如果无法避免,可以考虑在查询中使用 UNION ALL1 函数进行显式转换,但要注意这仍然可能导致索引失效。
SELECT * 的滥用* `SELECT ` 会选择表中所有的列,即使你只需要其中几列。这不仅增加了网络传输的开销,也增加了数据库处理结果集的内存负担,尤其是在大表JOIN时。 规避策略:** 永远只选择你需要的列。这不仅能提高查询性能,也能让你的SQL意图更清晰。
EXPLAIN分析是你的好朋友 最后,也是最重要的一点:当你遇到慢查询时,不要盲目猜测,使用 UNION ALL2 命令来分析查询的执行计划。它会告诉你查询是如何被执行的,包括JOIN类型(UNION ALL3 列)、是否使用了索引(UNION ALL4 列)、扫描了多少行(UNION ALL5 列)、以及其他重要的优化信息(UNION ALL6 列)。理解 UNION ALL2 的输出,是优化SQL查询的必修课。
EXPLAIN SELECT
o.order_id,
c.customer_name
FROM
orders o
INNER JOIN
customers c ON o.customer_id = c.customer_id
WHERE
o.order_date > '2023-01-01';
通过 UNION ALL2,你可以看到数据库是走了索引扫描(UNION ALL9 或 UNION0),还是全表扫描(UNION1),有没有使用临时表或文件排序等,这些都是判断查询性能好坏的关键指标。
以上就是MySQL JOIN类型与性能对比分析_Sublime中编写不同连接类型示例查询的详细内容,更多请关注php中文网其它相关文章!








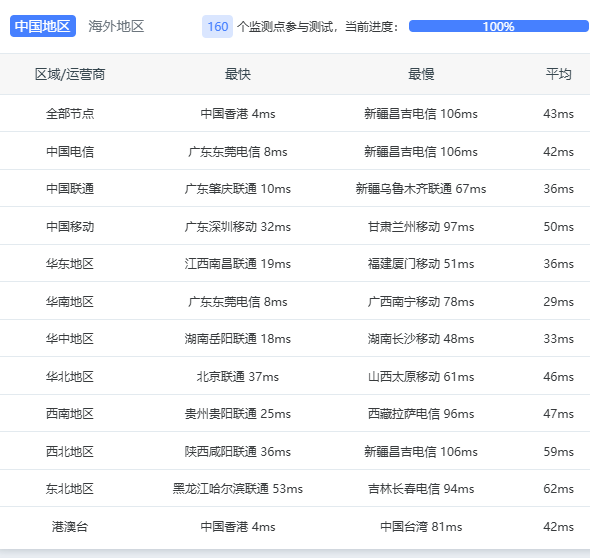 回国线路平均40ms左右,三网直连高峰期不跳线路!
回国线路平均40ms左右,三网直连高峰期不跳线路!