范式用于减少冗余、提高一致性,反范式用于提升性能;设计数据库时应优先使用范式,在性能瓶颈或查询复杂度过高时考虑反范式。一、范式能确保数据更新安全、结构清晰、减少异常,如用户和订单信息分离;二、反范式适用于频繁多表关联、读多写少、分布式系统及简化复杂sql的场景;三、做反范式时需控制范围、保持一致性机制、记录设计原因;四、建议初期按范式设计,上线后根据监控优化,报表系统可建宽表,缓存也可替代冗余。

数据库设计时,范式是基础,但不是绝对。什么时候该用范式,什么时候又需要考虑反范式? 简单来说:在保证数据一致性和结构清晰的前提下,当性能成为瓶颈、查询复杂度过高时,才考虑反范式设计。

下面从几个常见角度来看看具体怎么判断和操作。
一、什么是范式?优先使用范式?
范式(Normalization)是一种数据库设计方法,目的是减少冗余、提高数据一致性。常见的有第一范式(1NF)、第二范式(2NF)、第三范式(3NF),甚至BCNF等。

为什么要优先使用范式?
- 数据更新更安全:比如用户信息只存一份,修改时不会漏掉。
- 结构清晰:逻辑分离明确,容易维护和扩展。
- 减少数据异常:插入、删除、更新异常的概率降低。
举个例子,用户表和订单表分开存储,用户信息变更只需改一次,而不是每个订单都改一遍。

二、哪些情况下要考虑反范式?
反范式(Denormalization)是指有意引入冗余,以提升查询效率或简化结构。通常在以下几种场景中会考虑:
创客贴设计,一款智能在线设计工具,设计不求人,AI助你零基础完成专业设计!

51
-
频繁的多表关联影响性能
比如订单详情页经常要查用户姓名、商品名称,每次都连几张表,慢。 -
读多写少的业务场景
如报表系统、日志分析平台,数据一旦写入很少改动,适合缓存冗余字段。 -
分布式系统中跨库查询困难
分库分表后,JOIN成本很高,提前把常用字段复制过来,能省很多麻烦。 -
为避免复杂SQL而优化结构
某些业务逻辑下,SQL语句太长、嵌套太多,通过冗余可以简化代码逻辑。
三、如何做反范式设计?有哪些注意事项?
如果你决定使用反范式,有几个关键点需要注意:
- 控制范围:不要全盘反范式,只对数据或高频查询字段做冗余。
- 保持一致性机制:冗余字段需要有同步策略,比如触发器、定时任务或应用层更新。
- 记录设计原因:方便后期维护,避免“为什么这个字段存在两个表里”的困惑。
举个简单的例子:
假设你有一个订单表,里面原本只有 user_id,现在为了展示方便加了 user_name 字段。
这时候就要注意:
- 插入订单时,必须同时写入用户名;
- 用户名变更时,可能需要异步更新所有相关订单的用户名;
- 或者干脆不更新,接受一定时间内的“不一致”(比如允许显示旧名字几天)。
四、范式与反范式的平衡建议
实际开发中,范式为主、反式为辅是比较稳妥的做法。可以参考以下几个建议:
- 初期尽量按范式设计,避免过早优化;
- 上线后根据监控发现慢查询,再针对性地做反范式;
- 对于报表类系统,可以单独建宽表,不影响主业务模型;
- 使用缓存也是一种替代方案,不一定非要靠数据库冗余来提速。
基本上就这些。
范式是基础,反范式是手段,关键是看业务场景和性能需求。
以上就是MySQL数据库如何设计范式_何时需要考虑反范式设计?的详细内容,更多请关注php中文网其它相关文章!








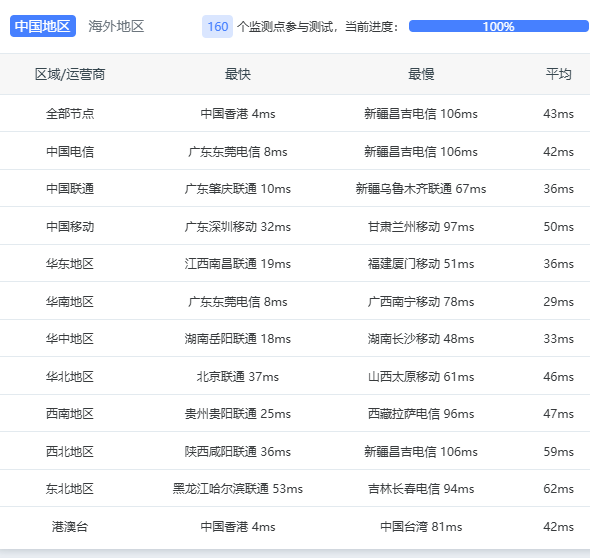 回国线路平均40ms左右,三网直连高峰期不跳线路!
回国线路平均40ms左右,三网直连高峰期不跳线路!