一、引言
在当今数字化时代,内容管理系统(CMS)已成为企业和个人发布、管理和检索大量文本内容的核心工具。随着内容规模的不断扩大,高效的全文检索功能变得至关重要。MySQL作为最流行的关系型数据库之一,其InnoDB引擎从5.6版本开始支持全文索引功能,为CMS提供了一种强大且便捷的文本检索解决方案。
然而,在实际应用中,CMS开发者和数据库管理员经常面临全文检索性能瓶颈。当内容量达到数十万甚至数百万条记录时,简单的全文检索实现可能导致响应时间延长、资源消耗增加,严重影响用户体验。特别是在高并发读写场景中,锁冲突问题可能进一步加剧性能问题。
二、InnoDB引擎下的全文检索功能详解
2.1 全文索引的基本概念与原理
InnoDB存储引擎从1.2.x版本开始支持全文索引技术,采用全倒排索引(full inverted index)方式实现高效的文本检索。倒排索引是一种将文本中的单词映射到包含这些单词的文档的索引结构,与传统的B+树索引不同,它更适合处理文本搜索场景。
在InnoDB的全文索引中,每个单词(word)对应一个文档ID和位置对列表(ilist)。例如,对于每个单词,存储了包含该单词的文档ID以及该单词在文档中的位置信息(字节偏移量)。这种结构允许InnoDB支持邻近搜索(proximity search),这是MyISAM全文索引所不具备的功能。
注意事项
2.2 全文索引的创建与管理
在InnoDB中创建全文索引相对简单,使用FULLTEXT关键字即可。例如,创建一个包含title和content列的全文索引:
CREATE TABLE articles (
id INT AUTO_INCREMENT PRIMARY KEY,
title VARCHAR(200) NOT NULL,
content TEXT NOT NULL,
FULLTEXT (title, content)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;需要注意的是,InnoDB的全文索引有一个特殊的FTS_DOC_ID列,类型为BIGINT UNSIGNED NOT NULL,存储引擎会自动在该列上创建一个名为FTS_DOC_ID_INDEX的唯一索引。
InnoDB的全文索引维护是延迟进行的,这意味着当文档被删除时,索引中的相关条目不会立即被删除,而是被记录在一个删除辅助表中。为了解决这个问题,可以使用OPTIMIZE TABLE命令手动清理已删除的记录:
SET GLOBAL innodb_optimize_fulltext_only=1;
OPTIMIZE TABLE articles;2.3 全文检索的三种查询模式
MySQL支持三种模式的全文检索查询,每种模式适用于不同的场景:
1. 自然语言模式(Natural Language Mode)
这是默认的全文检索模式,通过MATCH AGAINST传递特定字符串进行检索:
SELECT * FROM articles
WHERE MATCH(title, content)
AGAINST('database optimization');2. 布尔模式(Boolean Mode)
布尔模式允许使用布尔操作符构建更复杂的查询:
SELECT * FROM articles
WHERE MATCH(title, content)
AGAINST('+database -performance' IN BOOLEAN MODE);布尔操作符包括:+(必须包含)、-(必须排除)、>(提高相关性)、<(降低相关性)、*(通配符)、” “(短语匹配)
3. 查询扩展模式(Query Expansion Mode)
查询扩展模式执行两次检索:第一次使用给定的短语进行检索,第二次结合第一次相关性较高的结果进行扩展检索:
SELECT * FROM articles
WHERE MATCH(title, content)
AGAINST('database' WITH QUERY EXPANSION);2.4 中文全文检索的挑战与解决方案
MySQL原生的全文索引对中文支持不完善,因为中文没有明确的单词界定符。为了解决这个问题,可以使用第三方插件如ngram全文解析器:
安装ngram全文解析器插件
修改MySQL配置文件,添加:
ngram_token_size = 2重启MySQL服务
创建全文索引时指定使用ngram解析器:
CREATE FULLTEXT INDEX content ON articles(content) WITH PARSER ngram;三、CMS 场景下的全文检索性能瓶颈分析
3.1 索引构建与维护开销
在CMS应用中,随着内容的不断增加,全文索引的大小也会迅速增长。InnoDB的全文索引采用倒排索引结构,每个单词对应一个文档ID列表,这使得索引文件可能变得非常庞大。
解决方案
对于大表,可以考虑在业务低峰期创建或重建索引,或使用ALTER TABLE的ALGORITHM=INPLACE选项进行在线索引重建:
ALTER TABLE articles
DROP INDEX ft_content,
ADD FULLTEXT INDEX ft_content (content)
ALGORITHM=INPLACE;ALGORITHM=INPLACE允许在不重建整个表的情况下修改索引,减少锁表时间。
3.2 查询性能瓶颈
在CMS场景下,全文检索查询可能面临查询响应时间长、资源消耗高、相关性排序开销大等问题。
解决方案
3.3 锁机制与并发性能问题
InnoDB使用行级锁和多版本并发控制(MVCC)来支持高并发,但在全文检索场景下,仍然可能面临锁冲突问题。
解决方案
3.4 大数据量下的性能衰减
当CMS中的内容量达到数十万甚至数百万条记录时,全文检索的性能可能会显著下降,主要表现为磁盘I/O瓶颈、内存压力和查询执行计划问题。
解决方案
增加InnoDB缓冲池大小
使用分区表,将数据分散到不同物理存储设备
实施读写分离架构
对历史数据进行归档,减少活跃数据集的大小
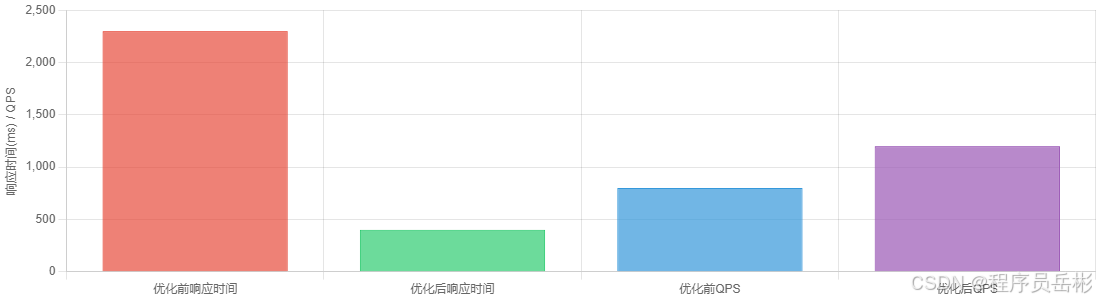
四、全文索引优化技巧与实践
4.1 索引设计优化策略
在设计全文索引时,应根据实际查询需求选择需要索引的列。通常,应优先索引经常用于搜索的列,如标题、摘要和内容。
关键策略
4.2 查询语句优化技巧
查询结构对性能有显著影响。应避免在MATCH子句中包含不必要的列,只包含与查询相关的列。
优化方法
4.3 服务器配置与参数调优
适当调整服务器配置参数,特别是InnoDB缓冲池大小和日志刷盘策略,可以显著提高全文检索性能。
对于内存为 32GB 的服务器,可以这样配置:
[mysqld]
innodb_buffer_pool_size = 24G
innodb_buffer_pool_instances = 4
innodb_flush_log_at_trx_commit = 2
tmp_table_size = 128M
max_heap_table_size = 128M4.4 高级优化技术
除了基本优化技巧,还可以采用一些高级技术进一步提升性能。
高级优化技术
使用查询扩展:平衡性能和相关性
实现渐进式搜索:用户输入时实时显示搜索结果
结合其他索引类型:提高复合查询性能
使用虚拟列和函数索引:优化特定类型的查询
实施读写分离架构:分发读操作到多个从服务器
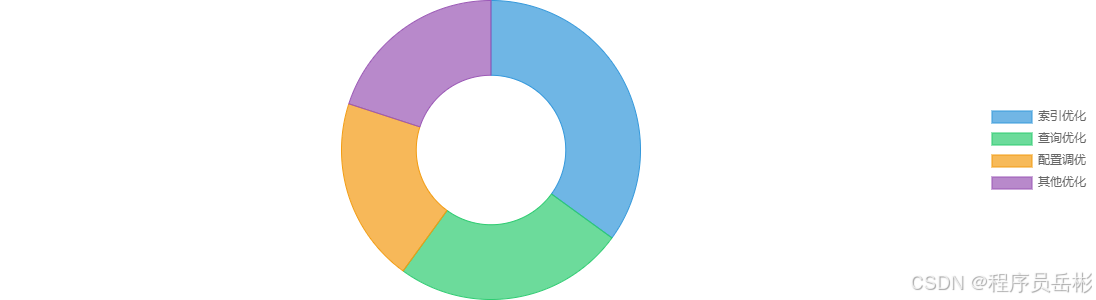
五、CMS 场景下的全文检索优化案例
5.1 案例一:新闻发布系统优化=
**场景描述:**一个新闻发布系统,包含100万篇文章,用户反馈搜索功能响应缓慢,特别是在搜索热门关键词时。
优化步骤:
优化效果:
5.2 案例二:知识库系统优化
场景描述:一个企业知识库系统,包含大量技术文档,用户需要频繁搜索特定主题的文档,但搜索结果相关性不高,且性能较差。
优化步骤:
优化效果:
六、结论与最佳实践
6.1 全文检索优化的核心原则
核心原则
6.2 CMS 场景下的全文检索最佳实践
基于本文的分析和案例研究,以下是针对CMS场景的全文检索最佳实践:
索引设计最佳实践
查询优化最佳实践
性能优化最佳实践
以上就是MySQL性能优化之全文检索查询优化实践的详细内容,更多关于MySQL全文检索查询优化的资料请关注Linux运维其它相关文章!


